Poor performance of pivot_wider #775
Description
The new pivot_wider is roughly twice as slow as the old spread (and reshape2::dcast) were.
library(tidyr)
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
mydf <- expand_grid(
case = sprintf("%03d", seq(1, 4000)),
year = seq(1900, 2000),
name = c("x", "y", "z")
) %>%
mutate(value = rnorm(nrow(.)))
bench::mark(
pivot = pivot_wider(mydf, names_from = "name", values_from = "value"),
spread = spread(mydf, name, value),
dcast = reshape2::dcast(mydf, case + year ~ name)
)
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.
#> # A tibble: 3 x 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 pivot 1.02s 1.02s 0.984 125MB 1.97
#> 2 spread 457.02ms 461.95ms 2.16 430MB 15.2
#> 3 dcast 449.15ms 472.34ms 2.12 457MB 11.6Created on 2019-10-10 by the reprex package (v0.3.0)
This performance penalty is prohibitively severe for some even larger datasets I'm working with.
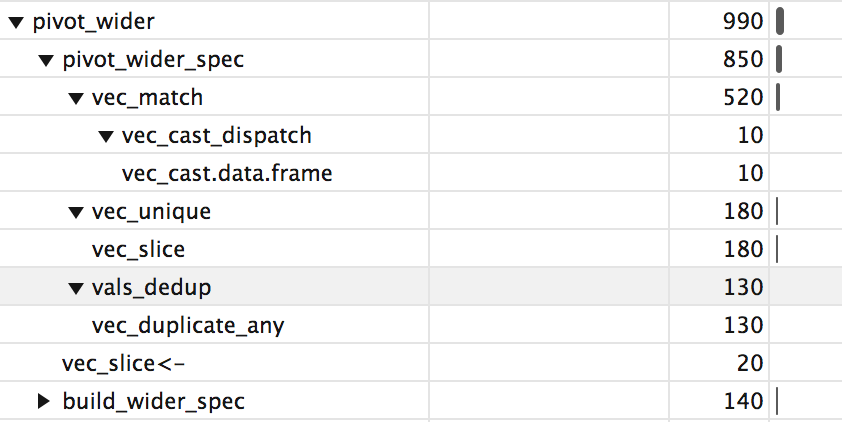
Based on some basic profvis, most of the time is spent in the actual pivoting operation (pivot_wider_spec), and in there, in the vctrs::vec_match function.