ERROR: core/context_gpu.cu:343: out of memory Error from operator #61
Description
Hi!
I tried to train the mask_rcnn with e2e_mask_rcnn_R-101-FPN_2x.yaml and 4 gpu, running the code
python2 tools/train_net.py
--multi-gpu-testing
--cfg configs/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml
OUTPUT_DIR result/m_4gpu
But I encouontered an error as follows.

I already checked the subprocess.py in my files refered to problem "c941633" and the code had already fixed. According to the following picture, which printed just few seconds before the network running error, I used {CUDA_VISIBLE_DEVICES 4,5,6,7}. And seems that truly it about ran out of memory.
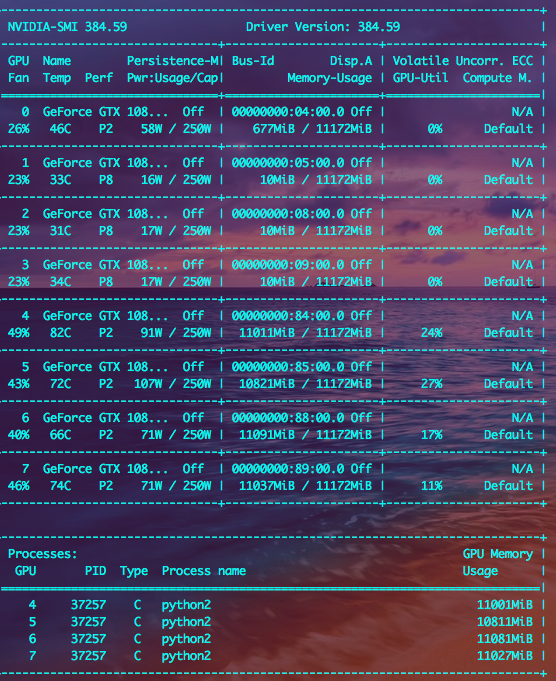
Is there anything wrong with my settings?Or maybe the project truly needs large memory?
My OS:Ubuntu 14.04.5 LTS (GNU/Linux 4.4.0-31-generic x86_64)
My cuda:Cuda compilation tools, release 8.0, V8.0.44
My cudnn:v5.1.5
Hope you can reply me soon.Thanks a lot!