Allow envs to send a 'needs_reset' signal#356
Conversation
|
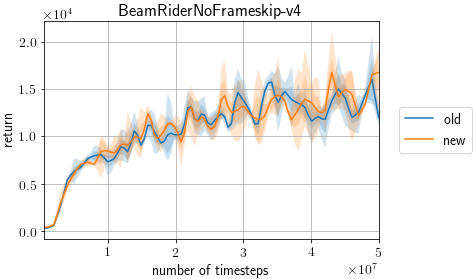
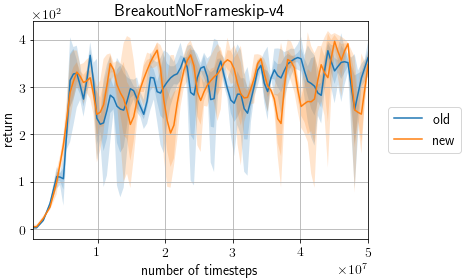
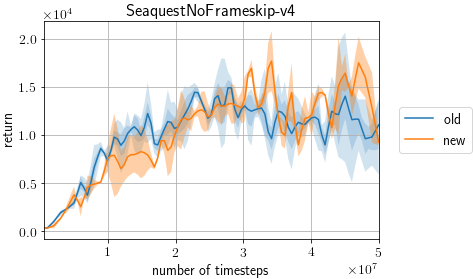
I confirmed the change introduced by this PR does not affect the scores on Atari. old:
|
 prabhatnagarajan
left a comment
prabhatnagarajan
left a comment
There was a problem hiding this comment.
I still have to dig deeper in another review.
| if done or episode_len == max_episode_len or t == steps: | ||
| reset = (episode_len == max_episode_len | ||
| or info.get('needs_reset', False)) | ||
| if done or reset or t == steps: |
There was a problem hiding this comment.
Later in this "if" statement (https://github.com/chainer/chainerrl/pull/356/files#diff-a2caf3ec0e2750a1d16edb375789daa5R81), you reset the environment. Why do you reset the environment if done is true? What if reset = False?
There was a problem hiding this comment.
Even if reset == False, we need to call env.reset() if done == True. In other words, the reset variable can be false when we reset the env due to done == True. It is possible to rename reset as non_done_reset or something, but it would be verbose.
There was a problem hiding this comment.
So this is targeted primarily at environments that reset based off of a max-episode-length or via done, and not environments where done is True but you still do not reset the environment?
There was a problem hiding this comment.
Correct. Currently, ChainerRL assumes that env.reset must be called when done==True.
| outdir, global_t, local_t, episode_r) | ||
| logger.info('statistics:%s', agent.get_statistics()) | ||
|
|
||
| # Evalaute the current agent |
There was a problem hiding this comment.
Nit: Evaluate*, not "Evalaute"
| @@ -86,9 +88,6 @@ def train_agent_batch(agent, env, steps, outdir, log_interval=None, | |||
| # 5. reset the env to start a new episode | |||
There was a problem hiding this comment.
Should these comments be revised?
There was a problem hiding this comment.
I think these comments are still correct except that 3-5 are skipped when training is finished. I'll clarify this in the comments.
|
|
||
| from gym import spaces | ||
|
|
||
| import chainerrl |
There was a problem hiding this comment.
Since you're changing the file, perhaps we should change the header from "This file is a fork from a MIT-licensed project" to "This file adapted from an MIT-licensed project..."
There was a problem hiding this comment.
"fork" means it already has changes, no?
| each episode, except that done=False is returned and that | ||
| info['needs_reset'] is set to True when past the limit. | ||
|
|
||
| Code that calls env.step is repsonsible for checking the info dict, the |
There was a problem hiding this comment.
"responsible" - typo
| parser.add_argument('--max-episode-len', type=int, | ||
| default=30 * 60 * 60 // 4, # 30 minutes with 60/4 fps | ||
| help='Maximum number of timesteps for each episode.') | ||
| parser.add_argument('--max-frames', type=int, |
There was a problem hiding this comment.
Is train_dqn_ale the only file that should have max_frames? At least atari/train_dqn.py should also incorporate these changes, right? Why did you only change the DQN example?
There was a problem hiding this comment.
Other examples that use atari_wrappers are affected as well. If the changes to examples/ale/train_dqn_ale.py look ok to you, I can apply the same changes to other examples as well, though I believe they would work without changes.
There was a problem hiding this comment.
Sounds good. I think we should still make the changes to other examples using atari_wrappers for completeness/consistency.
prabhatnagarajan
left a comment
There was a problem hiding this comment.
I've read through this PR, and everything seems to be okay. was slightly confused by some of the tests, but they all seemed fine. This is ready for approval, but please make the following minor changes before merging with master:
- [Address the comments (e.g. typos etc.)]
- [Make the changes to train_dqn_ale.py apply to other relevant files]
| parser.add_argument('--max-episode-len', type=int, | ||
| default=30 * 60 * 60 // 4, # 30 minutes with 60/4 fps | ||
| help='Maximum number of timesteps for each episode.') | ||
| parser.add_argument('--max-frames', type=int, |
There was a problem hiding this comment.
Sounds good. I think we should still make the changes to other examples using atari_wrappers for completeness/consistency.
|
I addressed the comments and made the same change to other examples. |
This PR enables an env to send a signal that indicates it needs a reset via the
infodict returned byenv.stepwithout settingdone=True.This functionality is needed to implement to strictly follow the training protocol of DeepMind on Atari games, which limits the number of frames of an episode ignoring life losses, while the agent still sees episodes that terminate by a life loss.