[SPARK-40307][PYTHON] Introduce Arrow-optimized Python UDFs #39384
Conversation
| is_func_with_args = len(getfullargspec(f).args) > 0 | ||
| except TypeError: | ||
| is_func_with_args = False | ||
| is_output_atomic_type = ( |
There was a problem hiding this comment.
The limitation ought to be eliminated as a follow-up.
python/pyspark/sql/udf.py
Outdated
| # +-----------------------------+--------------+----------+------+------+----------------+-----------------------------+----------+----------------------+---------+-----------+----------------------------+----------+--------------+ # noqa | ||
| # |SQL Type \ Python Value(Type)|None(NoneType)|True(bool)|1(int)|a(str)|1970-01-01(date)|1970-01-01 00:00:00(datetime)|1.0(float)|array('i', [1])(array)|[1](list)|(1,)(tuple)|bytearray(b'ABC')(bytearray)|1(Decimal)|{'a': 1}(dict)| # noqa | ||
| # +-----------------------------+--------------+----------+------+------+----------------+-----------------------------+----------+----------------------+---------+-----------+----------------------------+----------+--------------+ # noqa | ||
| # | boolean| X| X| X| X| X| X| X| X| X| X| X| X| X| # noqa |
There was a problem hiding this comment.
Why is it all X? X means an error.
There was a problem hiding this comment.
Good catch! I re-generated the table and added a note for the library versions used.
$ conda list | grep -e 'python\|pyarrow\|pandas'
pandas 1.5.2 pypi_0 pypi
pandas-stubs 1.2.0.53 pypi_0 pypi
pyarrow 10.0.1 pypi_0 pypi
python 3.9.15 h218abb5_2
python-dateutil 2.8.2 pypi_0 pypi
| self.assertEquals(row[0], "[1 2 3]") | ||
| self.assertEquals(row[1], "{'a': 'b'}") | ||
|
|
||
| def test_useArrow(self): |
There was a problem hiding this comment.
Let's name it test_use_arrow
There was a problem hiding this comment.
Sounds good! Renamed.
|
Can one of the admins verify this patch? |
|
Test failures in CI jobs are irrelevant to the PR. I'll rebase the PR to the latest master. |
274238f to
6101552
Compare
6101552 to
2a5c54c
Compare
|
Thank you both! Merged to master. |
### What changes were proposed in this pull request? Introduce Arrow-optimized Python UDFs. Please refer to [design](https://docs.google.com/document/d/e/2PACX-1vQxFyrMqFM3zhDhKlczrl9ONixk56cVXUwDXK0MMx4Vv2kH3oo-tWYoujhrGbCXTF78CSD2kZtnhnrQ/pub) for design details and micro benchmarks. There are two ways to enable/disable the Arrow optimization for Python UDFs: - the Spark configuration `spark.sql.execution.pythonUDF.arrow.enabled`, disabled by default. - the `useArrow` parameter of the `udf` function, None by default. The Spark configuration takes effect only when `useArrow` is None. Otherwise, `useArrow` decides whether a specific user-defined function is optimized by Arrow or not. The reason why we introduce these two ways is to provide both a convenient, per-Spark-session control and a finer-grained, per-UDF control of the Arrow optimization for Python UDFs. ### Why are the changes needed? Python user-defined function (UDF) enables users to run arbitrary code against PySpark columns. It uses Pickle for (de)serialization and executes row by row. One major performance bottleneck of Python UDFs is (de)serialization, that is, the data interchanging between the worker JVM and the spawned Python subprocess which actually executes the UDF. The PR proposes a better alternative to handle the (de)serialization: Arrow, which is used in the (de)serialization of Pandas UDF already. #### Benchmark The micro benchmarks are conducted in a cluster with 1 driver (i3.2xlarge), 2 workers (i3.2xlarge). An i3.2xlarge machine has 61 GB Memory, 8 Cores. The datasets used in the benchmarks are generated and sized 5 GB, 10 GB, 20 GB and 40 GB. As shown below, Arrow-optimized Python UDFs are **~1.4x** faster than non-Arrow-optimized Python UDFs. 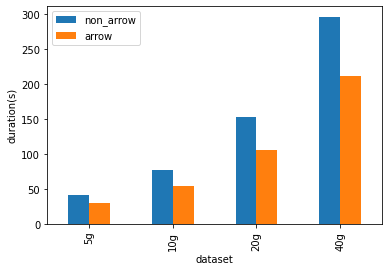 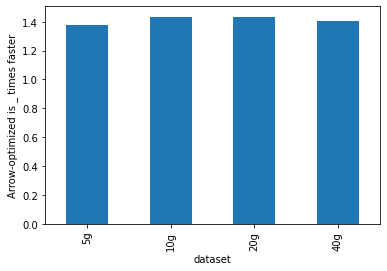 Please refer to [design](https://docs.google.com/document/d/e/2PACX-1vQxFyrMqFM3zhDhKlczrl9ONixk56cVXUwDXK0MMx4Vv2kH3oo-tWYoujhrGbCXTF78CSD2kZtnhnrQ/pub) for details. ### Does this PR introduce _any_ user-facing change? No, since the Arrow optimization for Python UDFs is disabled by default. ### How was this patch tested? Unit tests. Below is the script to generate the result table when the Arrow's type coercion is needed, as in the [docstring](https://github.com/apache/spark/pull/39384/files#diff-2df611ab00519d2d67e5fc20960bd5a6bd76ecd6f7d56cd50d8befd6ce30081bR96-R111) of `_create_py_udf` . ``` import sys import array import datetime from decimal import Decimal from pyspark.sql import Row from pyspark.sql.types import * from pyspark.sql.functions import udf data = [ None, True, 1, "a", datetime.date(1970, 1, 1), datetime.datetime(1970, 1, 1, 0, 0), 1.0, array.array("i", [1]), [1], (1,), bytearray([65, 66, 67]), Decimal(1), {"a": 1}, ] types = [ BooleanType(), ByteType(), ShortType(), IntegerType(), LongType(), StringType(), DateType(), TimestampType(), FloatType(), DoubleType(), BinaryType(), DecimalType(10, 0), ] df = spark.range(1) results = [] count = 0 total = len(types) * len(data) spark.sparkContext.setLogLevel("FATAL") for t in types: result = [] for v in data: try: row = df.select(udf(lambda _: v, t)("id")).first() ret_str = repr(row[0]) except Exception: ret_str = "X" result.append(ret_str) progress = "SQL Type: [%s]\n Python Value: [%s(%s)]\n Result Python Value: [%s]" % ( t.simpleString(), str(v), type(v).__name__, ret_str) count += 1 print("%s/%s:\n %s" % (count, total, progress)) results.append([t.simpleString()] + list(map(str, result))) schema = ["SQL Type \\ Python Value(Type)"] + list(map(lambda v: "%s(%s)" % (str(v), type(v).__name__), data)) strings = spark.createDataFrame(results, schema=schema)._jdf.showString(20, 20, False) print("\n".join(map(lambda line: " # %s # noqa" % line, strings.strip().split("\n")))) ``` Closes apache#39384 from xinrong-meng/arrow_py_udf_init. Authored-by: Xinrong Meng <[email protected]> Signed-off-by: Xinrong Meng <[email protected]>
{kind=link}
{kind=link}
| cls.spark.conf.set("spark.sql.execution.pythonUDF.arrow.enabled", "false") | ||
|
|
||
|
|
||
| def test_use_arrow(self): |
There was a problem hiding this comment.
@xinrong-meng Who runs this test?
There was a problem hiding this comment.
Good catch! Removed it 63ef94e. test_use_arrow is duplicated in PythonUDFArrowTestsMixin of test_arrow_python_udf.py.
…onnect ### What changes were proposed in this pull request? Implement Arrow-optimized Python UDFs in Spark Connect. Please see #39384 for motivation and performance improvements of Arrow-optimized Python UDFs. ### Why are the changes needed? Parity with vanilla PySpark. ### Does this PR introduce _any_ user-facing change? Yes. In Spark Connect Python Client, users can: 1. Set `useArrow` parameter True to enable Arrow optimization for a specific Python UDF. ```sh >>> df = spark.range(2) >>> df.select(udf(lambda x : x + 1, useArrow=True)('id')).show() +------------+ |<lambda>(id)| +------------+ | 1| | 2| +------------+ # ArrowEvalPython indicates Arrow optimization >>> df.select(udf(lambda x : x + 1, useArrow=True)('id')).explain() == Physical Plan == *(2) Project [pythonUDF0#18 AS <lambda>(id)#16] +- ArrowEvalPython [<lambda>(id#14L)#15], [pythonUDF0#18], 200 +- *(1) Range (0, 2, step=1, splits=1) ``` 2. Enable `spark.sql.execution.pythonUDF.arrow.enabled` Spark Conf to make all Python UDFs Arrow-optimized. ```sh >>> spark.conf.set("spark.sql.execution.pythonUDF.arrow.enabled", True) >>> df.select(udf(lambda x : x + 1)('id')).show() +------------+ |<lambda>(id)| +------------+ | 1| | 2| +------------+ # ArrowEvalPython indicates Arrow optimization >>> df.select(udf(lambda x : x + 1)('id')).explain() == Physical Plan == *(2) Project [pythonUDF0#30 AS <lambda>(id)#28] +- ArrowEvalPython [<lambda>(id#26L)#27], [pythonUDF0#30], 200 +- *(1) Range (0, 2, step=1, splits=1) ``` ### How was this patch tested? Parity unit tests. Closes #40725 from xinrong-meng/connect_arrow_py_udf. Authored-by: Xinrong Meng <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
What changes were proposed in this pull request?
Introduce Arrow-optimized Python UDFs. Please refer to design for design details and micro benchmarks.
There are two ways to enable/disable the Arrow optimization for Python UDFs:
spark.sql.execution.pythonUDF.arrow.enabled, disabled by default.useArrowparameter of theudffunction, None by default.The Spark configuration takes effect only when
useArrowis None. Otherwise,useArrowdecides whether a specific user-defined function is optimized by Arrow or not.The reason why we introduce these two ways is to provide both a convenient, per-Spark-session control and a finer-grained, per-UDF control of the Arrow optimization for Python UDFs.
Why are the changes needed?
Python user-defined function (UDF) enables users to run arbitrary code against PySpark columns. It uses Pickle for (de)serialization and executes row by row.
One major performance bottleneck of Python UDFs is (de)serialization, that is, the data interchanging between the worker JVM and the spawned Python subprocess which actually executes the UDF.
The PR proposes a better alternative to handle the (de)serialization: Arrow, which is used in the (de)serialization of Pandas UDF already.
Benchmark
The micro benchmarks are conducted in a cluster with 1 driver (i3.2xlarge), 2 workers (i3.2xlarge). An i3.2xlarge machine has 61 GB Memory, 8 Cores. The datasets used in the benchmarks are generated and sized 5 GB, 10 GB, 20 GB and 40 GB.
As shown below, Arrow-optimized Python UDFs are ~1.4x faster than non-Arrow-optimized Python UDFs.
Please refer to design for details.
Does this PR introduce any user-facing change?
No, since the Arrow optimization for Python UDFs is disabled by default.
How was this patch tested?
Unit tests.
Below is the script to generate the result table when the Arrow's type coercion is needed, as in the docstring of
_create_py_udf.SPARK-40307