[SPARK-21743][SQL] top-most limit should not cause memory leak #18955
Conversation
| @@ -2658,4 +2658,9 @@ class SQLQuerySuite extends QueryTest with SharedSQLContext { | |||
| checkAnswer(sql("SELECT __auto_generated_subquery_name.i from (SELECT i FROM v)"), Row(1)) | |||
| } | |||
| } | |||
|
|
|||
| test("SPARK-21743: top-most limit should not cause memory leak") { | |||
| // In unit test, Spark will fail the query if memory leak detected. | |||
There was a problem hiding this comment.
Without the fix, the test did not fail, but I saw the warning message:
22:05:07.455 WARN org.apache.spark.executor.Executor: Managed memory leak detected; size = 33554432 bytes, TID = 2
With the fix, the warning message is gone.
There was a problem hiding this comment.
did you try this test in spark shell? We only throw exception for memory leak if spark.unsafe.exceptionOnMemoryLeak is true. But this config is false by default, and is true in unit test.
There was a problem hiding this comment.
When this is also executed on Intellij, this test does not fail. How about this?
class SQLQuerySparkContextSuite extends QueryTest with LocalSparkContext {
val spark = SparkSession
.builder()
.config("spark.unsafe.exceptionOnMemoryLeak", "true")
.master("local[1]")
.getOrCreate()
test("SPARK-21743: top-most limit should not cause memory leak") {
spark.range(100).groupBy("id").count().limit(1).collect()
}
}
There was a problem hiding this comment.
That should be fine, as long as our test framework can capture it. : )
There was a problem hiding this comment.
This issue is fixed in #18967
I think we need to move this test case to DataFrameSuite
There was a problem hiding this comment.
How about just adding it in Ah, seems like Xiao already did that.TestSparkSession instead?
|
Test build #80713 has finished for PR 18955 at commit
|
|
Test build #80726 has finished for PR 18955 at commit
|
| @@ -474,6 +474,10 @@ case class CollapseCodegenStages(conf: SQLConf) extends Rule[SparkPlan] { | |||
| } | |||
|
|
|||
| private def supportCodegen(plan: SparkPlan): Boolean = plan match { | |||
| // Do not enable whole stage codegen for a single limit. | |||
| case limit: BaseLimitExec if !limit.child.isInstanceOf[CodegenSupport] || | |||
| !limit.child.asInstanceOf[CodegenSupport].supportCodegen => | |||
There was a problem hiding this comment.
We can also override LocalLimitExec.supportCodegen and make that depend on the child.supportCodegen. That seems more elegant that to special case it here.
| // Normally wrapping child with `LocalLimitExec` here is a no-op, because | ||
| // `CollectLimitExec.executeCollect` will call `LogicalLimitExec.executeTake`, which | ||
| // calls `child.executeTake`. If child supports whole stage codegen, adding this | ||
| // `LocalLimitExec` can break the input consuming loop inside whole stage codegen and |
There was a problem hiding this comment.
By ...break the input consuming loop... you mean stop processing, and break whole stage code gen. We may need to word this slightly differently :)...
|
LGTM - pending jenkins |
|
|
||
| override def executeTake(n: Int): Array[InternalRow] = child.executeTake(math.min(n, limit)) | ||
|
|
||
| override def executeCollect(): Array[InternalRow] = child.executeTake(limit) |
There was a problem hiding this comment.
executeTake looks good. But should executeCollect be the same for LocalLimitExec and GlobalLimitExec?
doExecute is an example. For LocalLimitExec, it takes limit rows in each partition. For GlobalLimitExec, it takes limit rows in single partition.
Previously executeCollect retrieves limit rows from each partition. After this change, executeCollect for LocalLimitExec retrieves only limit rows.
There was a problem hiding this comment.
Seems this fix relies CollectLimitExec.executeCollect to call LocalLimitExec.executeTake. Looks like we don't need to change executeCollect?
| @@ -72,7 +72,12 @@ abstract class SparkStrategies extends QueryPlanner[SparkPlan] { | |||
| execution.TakeOrderedAndProjectExec( | |||
| limit, order, projectList, planLater(child)) :: Nil | |||
| case logical.Limit(IntegerLiteral(limit), child) => | |||
| execution.CollectLimitExec(limit, planLater(child)) :: Nil | |||
| // Normally wrapping child with `LocalLimitExec` here is a no-op, because | |||
| // `CollectLimitExec.executeCollect` will call `LogicalLimitExec.executeTake`, which | |||
There was a problem hiding this comment.
typo? LogicalLimitExec -> LocalLimitExec.
|
LGTM except for the question with |
|
Test build #80738 has finished for PR 18955 at commit
|
|
Retest this please. |
|
Test build #80746 has finished for PR 18955 at commit
|
|
LGTM |
|
Test build #80756 has finished for PR 18955 at commit
|
|
Thanks! Merging to master. |
…leak ## What changes were proposed in this pull request? This is a follow-up of apache#18955 , to fix a bug that we break whole stage codegen for `Limit`. ## How was this patch tested? existing tests. Author: Wenchen Fan <[email protected]> Closes apache#18993 from cloud-fan/bug.
## What changes were proposed in this pull request?
There is a performance regression in Spark 2.3. When we read a big compressed text file which is un-splittable(e.g. gz), and then take the first record, Spark will scan all the data in the text file which is very slow. For example, `spark.read.text("/tmp/test.csv.gz").head(1)`, we can check out the SQL UI and see that the file is fully scanned.
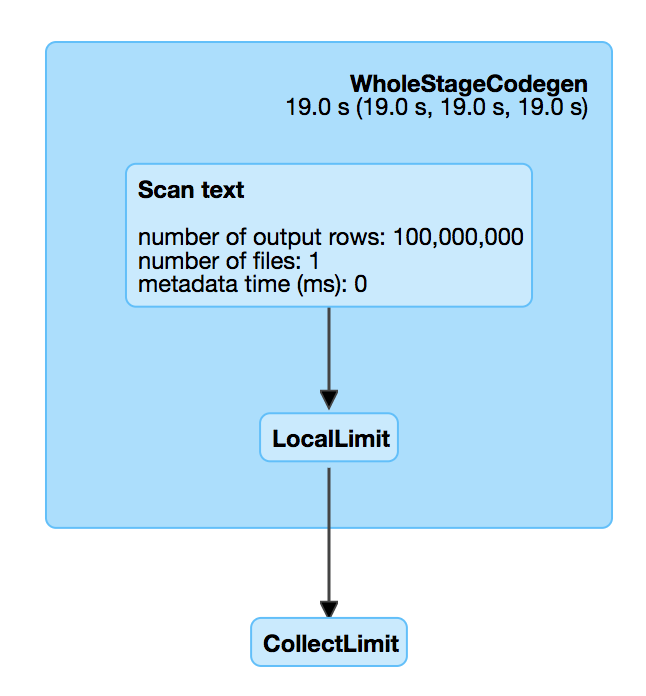
This is introduced by #18955 , which adds a LocalLimit to the query when executing `Dataset.head`. The foundamental problem is, `Limit` is not well whole-stage-codegened. It keeps consuming the input even if we have already hit the limitation.
However, if we just fix LIMIT whole-stage-codegen, the memory leak test will fail, as we don't fully consume the inputs to trigger the resource cleanup.
To fix it completely, we should do the following
1. fix LIMIT whole-stage-codegen, stop consuming inputs after hitting the limitation.
2. in whole-stage-codegen, provide a way to release resource of the parant operator, and apply it in LIMIT
3. automatically release resource when task ends.
Howere this is a non-trivial change, and is risky to backport to Spark 2.3.
This PR proposes to revert #18955 in Spark 2.3. The memory leak is not a big issue. When task ends, Spark will release all the pages allocated by this task, which is kind of releasing most of the resources.
I'll submit a exhaustive fix to master later.
## How was this patch tested?
N/A
Author: Wenchen Fan <[email protected]>
Closes #21573 from cloud-fan/limit.
{kind=link}
There is a performance regression in Spark 2.3. When we read a big compressed text file which is un-splittable(e.g. gz), and then take the first record, Spark will scan all the data in the text file which is very slow. For example, `spark.read.text("/tmp/test.csv.gz").head(1)`, we can check out the SQL UI and see that the file is fully scanned.

This is introduced by apache#18955 , which adds a LocalLimit to the query when executing `Dataset.head`. The foundamental problem is, `Limit` is not well whole-stage-codegened. It keeps consuming the input even if we have already hit the limitation.
However, if we just fix LIMIT whole-stage-codegen, the memory leak test will fail, as we don't fully consume the inputs to trigger the resource cleanup.
To fix it completely, we should do the following
1. fix LIMIT whole-stage-codegen, stop consuming inputs after hitting the limitation.
2. in whole-stage-codegen, provide a way to release resource of the parant operator, and apply it in LIMIT
3. automatically release resource when task ends.
Howere this is a non-trivial change, and is risky to backport to Spark 2.3.
This PR proposes to revert apache#18955 in Spark 2.3. The memory leak is not a big issue. When task ends, Spark will release all the pages allocated by this task, which is kind of releasing most of the resources.
I'll submit a exhaustive fix to master later.
N/A
Author: Wenchen Fan <[email protected]>
Closes apache#21573 from cloud-fan/limit.
(cherry picked from commit d3255a5)
RB=1435935
BUG=LIHADOOP-40677
G=superfriends-reviewers
R=fli,mshen,yezhou,edlu
A=yezhou
What changes were proposed in this pull request?
For top-most limit, we will use a special operator to execute it:
CollectLimitExec.CollectLimitExecwill retrieven(which is the limit) rows from each partition of the child plan output, see https://github.com/apache/spark/blob/v2.2.0/sql/core/src/main/scala/org/apache/spark/sql/execution/SparkPlan.scala#L311. It's very likely that we don't exhaust the child plan output.This is fine when whole-stage-codegen is off, as child plan will release the resource via task completion listener. However, when whole-stage codegen is on, the resource can only be released if all output is consumed.
To fix this memory leak, one simple approach is, when
CollectLimitExecretrievenrows from child plan output, child plan output should only havenrows, then the output is exhausted and resource is released. This can be done by wrapping child plan withLocalLimitHow was this patch tested?
a regression test