Self play: Add a ghost trainer and track agents elo rating #1975
Conversation
Change the rewards to promote competition Send a text observation with the winner of each match Use a Learning Brain and a ghost brain playing against each other Add logging to track the winrates and if the agents are getting better.
A ghost trainer manages several policies and assign them randomly to several agents.
These policies' graphs are loaded randomly from saved models of a master trainer on each academy reset.
Add an elo parameter to models to track their elo rating.
Elo rating is updated by getting results of the matches between agents from text observations.
|
hi - this is awesome. we need a couple of weeks to review, but wanted to put it on your radar we are looking at it. |
|
Oki doki, thanks for the heads up :)
…On Tue, Apr 30, 2019 at 10:39 PM Jeffrey Shih ***@***.***> wrote:
hi - this is awesome. we need a couple of weeks to review, but wanted to
put it on your radar we are looking at it.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#1975 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ACTJSNSTLXQOFVDIVVMXWYLPTCVAPANCNFSM4HH3MHVQ>
.
|
|
Hi @LeSphax, Thanks for your contribution, I've tried to use it on my project but I'm having some issues and some questions.
Here's a screenshot of my learning scene, red player have to score in the blue zone and vice-versa. Thanks, |

|
Hi @AcelisWeaven, Unfortunately I am on holidays without my computer and it has been a while since I looked at this but let's see if I can help anyway :)
If that doesn't help the way I debugged that kind of problem is to have only two agents training, don't switch the brain between them and log all the match results to check that they make sense.
I will try to get hold of a computer this weekend and see if I can investigate that memory leak. |
|
Thanks @LeSphax for your quick answer!
Edit: I also forgot to mention that I'm using Anaconda on Windows 10 to manage my env, and that I'm running tensorflow-cpu. I'm using your fork with the latest master updates (using a rebase) |
|
|
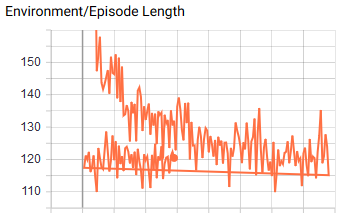
… using them so the buffer just got bigger and bigger
|
Hey @AcelisWeaven , I finally spent some time investigating this memory leak (actually there were two). I believe my two latest commits should fix it. There is also a third memory leak that happens when you run only in inference mode but it seems like this one was already in the framework in that version. To fix it I will need to update the PR to the latest develop branch. |
|
Hey @LeSphax ! I've been running it for 24h+ and everything works flawlessly. Thanks! Edit: The longer sessions allowed me to find some issues in my environment, and since I fixed those, the training process is a lot better. I still have a little issue after 48h+ training (without crash!), were nothing happen anymore. It may be coming from my environment so I'll take a closer look. Edit 2: Definitely come from my environment (the ball can sometime be stuck "inside" the wall). |
| policy_used_ckpts = all_ckpts | ||
|
|
||
| # There is a 1-p_load_from_all_checkpoints probability that we sample the policy only from the last load_from_last_N_checkpoints policies | ||
| if random.random() > self.ghost_prob_sample_only_recent: |
There was a problem hiding this comment.
@LeSphax Shouldn't this condition be reversed, according to the explanation? To me it seems that it'll have only 40% chances to pick a recent checkpoints list.
ghost_prob_sample_only_recent: Probability that the ghost will only sample recent checkpoints instead of the whole history. 0.6 means 60% chance to sample recent and 40% to sample the whole history.
| if random.random() > self.ghost_prob_sample_only_recent: | |
| if random.random() < self.ghost_prob_sample_only_recent: |
|
Sorry, this got automatically closed when we deleted the |
|
Changing target from develop to master. |
|
This has diverged a lot from master. I wouldn't mind doing a rebase but I can't figure out why this PR wasn't merged/declined months ago and don't want to waste the effort if the maintainers have a reason why they didn't like this. |
|
Hey @elliott-omosheye, I didn't work on this PR in a while but last time I discussed it with the maintainers it was in this issue #2559. The status at that time was I don't mind doing the rebase myself if/when we want to merge it. |
|
This feature has been added in #3194. Thanks for the initial PR! |
Does that mean this feature will be available in the next release? |
|
Yes. |
See #1070 for more context around this pull-request.
Ghost trainer
This pull request adds a new type of trainer, the ghost, which allows an agent to play against past versions of himself.
The ghost manages several policies, each with a different past version of the agent.
The ghost brain doesn't update his weights, he is assigned to a master ppo trainer and use the master trainer's past checkpoints. On academy resets, the ghost randomly samples the ppo trainer's checkpoints and load them into its policies.
Ghost configuration in trainer_config.yaml:
TennisLearning:
normalize: true
max_steps: 2e5
use_elo_rating: true
TennisGhost:
trainer: ghost
ghost_master_brain: TennisLearning
ghost_num_policies: 3
ghost_prob_sample_only_recent: 0.6
ghost_recent_ckpts_threshold: 10
I also wanted to give some control around the sampling of checkpoints so I added those parameters:
The unity side can decide which agent is using the ghost brain and which agent is using the learning brain. Changing those assignments is also supported
Elo rating:
When using self-play, measuring rewards is not very helpful because better agents might be good at preventing each other from getting rewards.
One way to measure progression then is elo rating.
Each agent has an elo rating and agents will play matches against each other. The winner of the match gains rating and the loser loses rating, the amount they win/lose depends on their respective ratings before the match.
Elo rating is stored in the models, allowing each policy to know its own elo rating when loading a graph.
The match results are sent by agents in the CollectObservations method in this form
"opponent_agent_id|match_result".
So for example: "1234|win", "1234|loss" or "4321|playing".
Tennis Environment
What I just described was implemented on the python side and I also modified the Tennis Example to use self-play.
I added the TennisGhost, some winrate metrics to help me debug and I changed the reward settings to encourage winning matches instead of encouraging as many passes as possible.
So you can test this on the Tennis Environment. The results are a bit noisy, but it usually gets around 1240-1270 elo rating at 25000 steps with
trainer_config.yamland--save-freq=5000.There are a few things I am not sure about:
So this pull-request might not be complete enough yet, but I felt like I should ask for feedback to make sure that this is something that should be in ML agents before proceeding.
If anything doesn't make sense feel free to ask me :)