Both DP or DDP not works on A100. #14630
Description
🐛 Bug
The strategy of DP or DDP not works. They stuck here:
DDP:

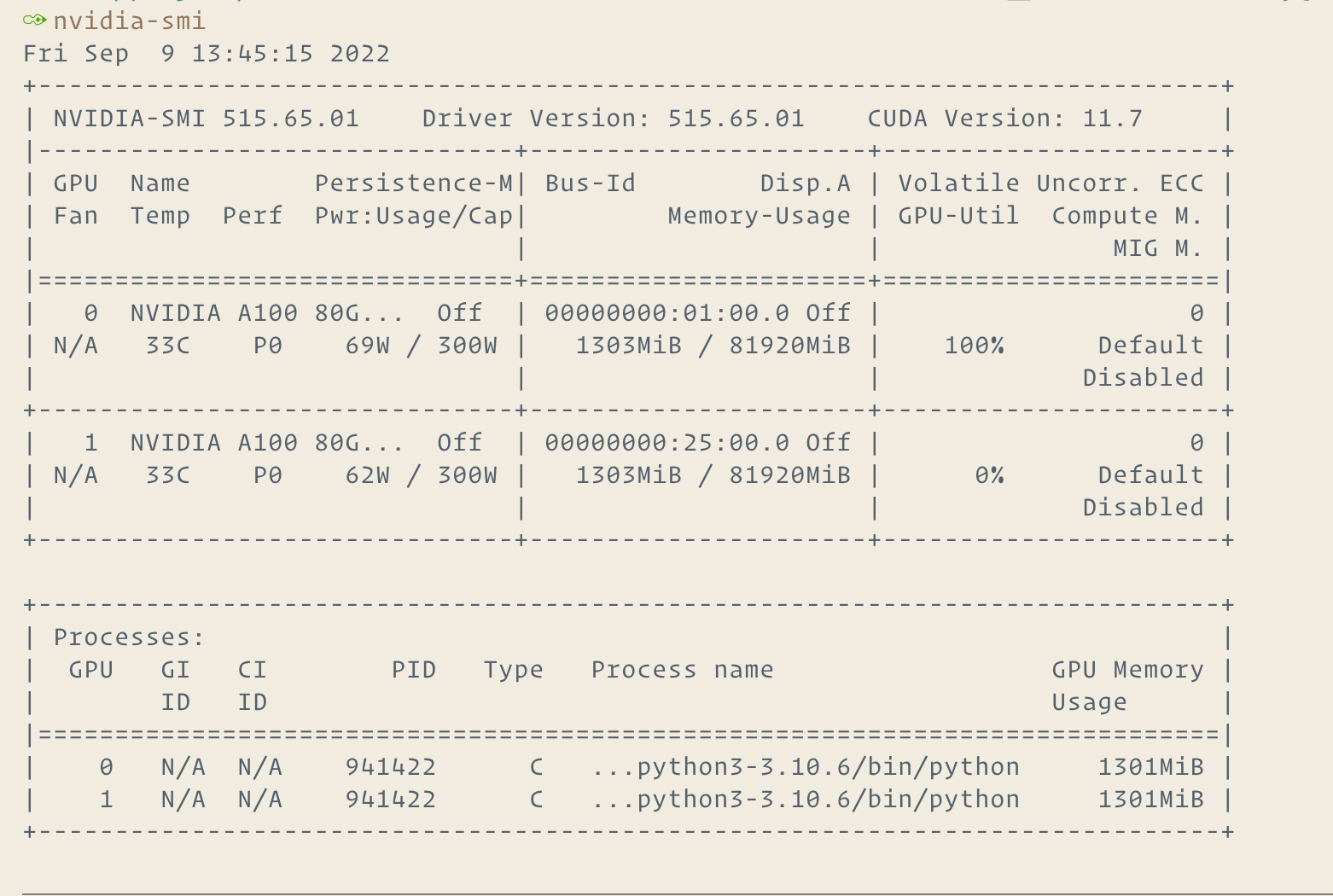
And use all of the GPU:
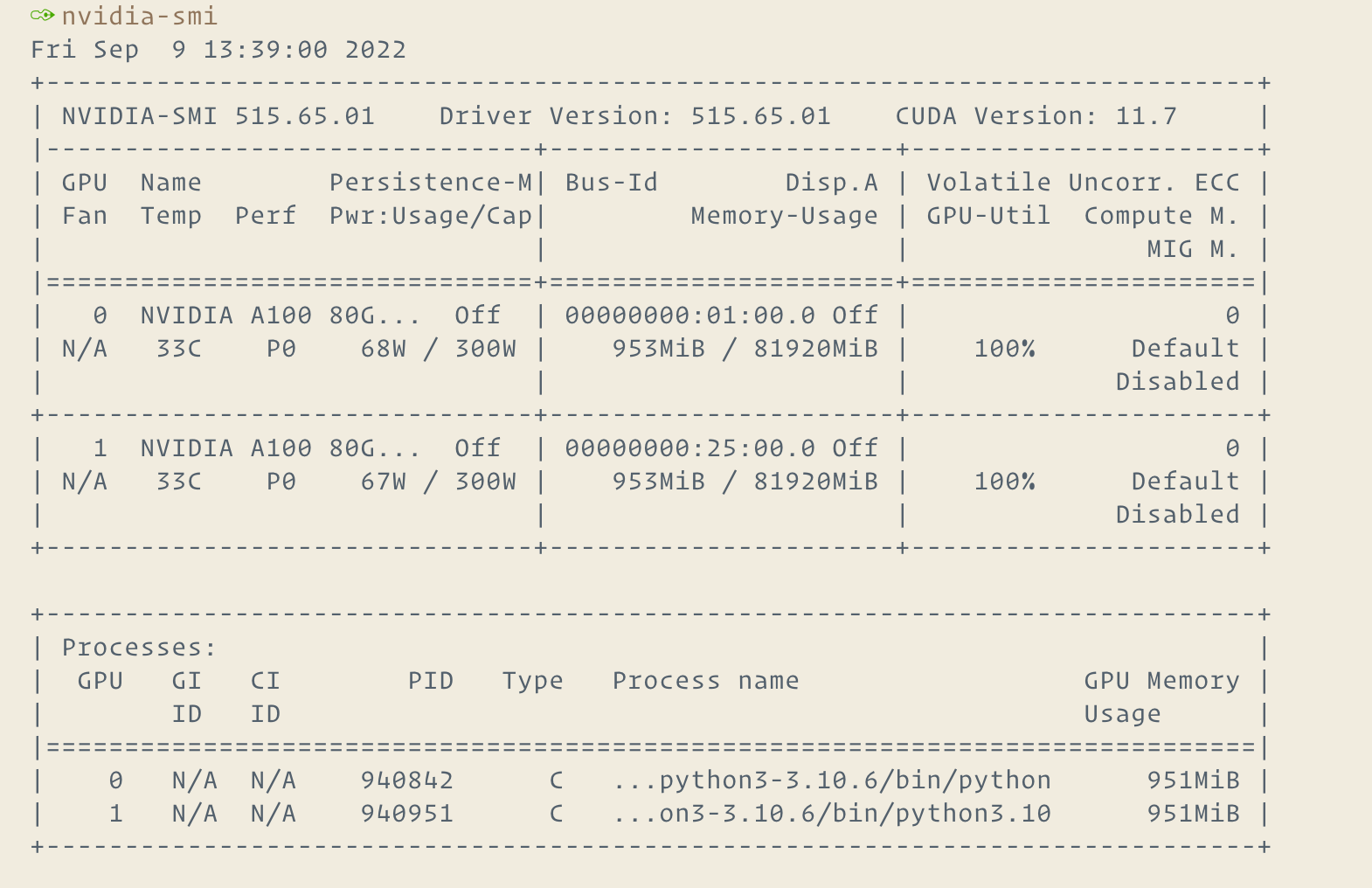
DP:
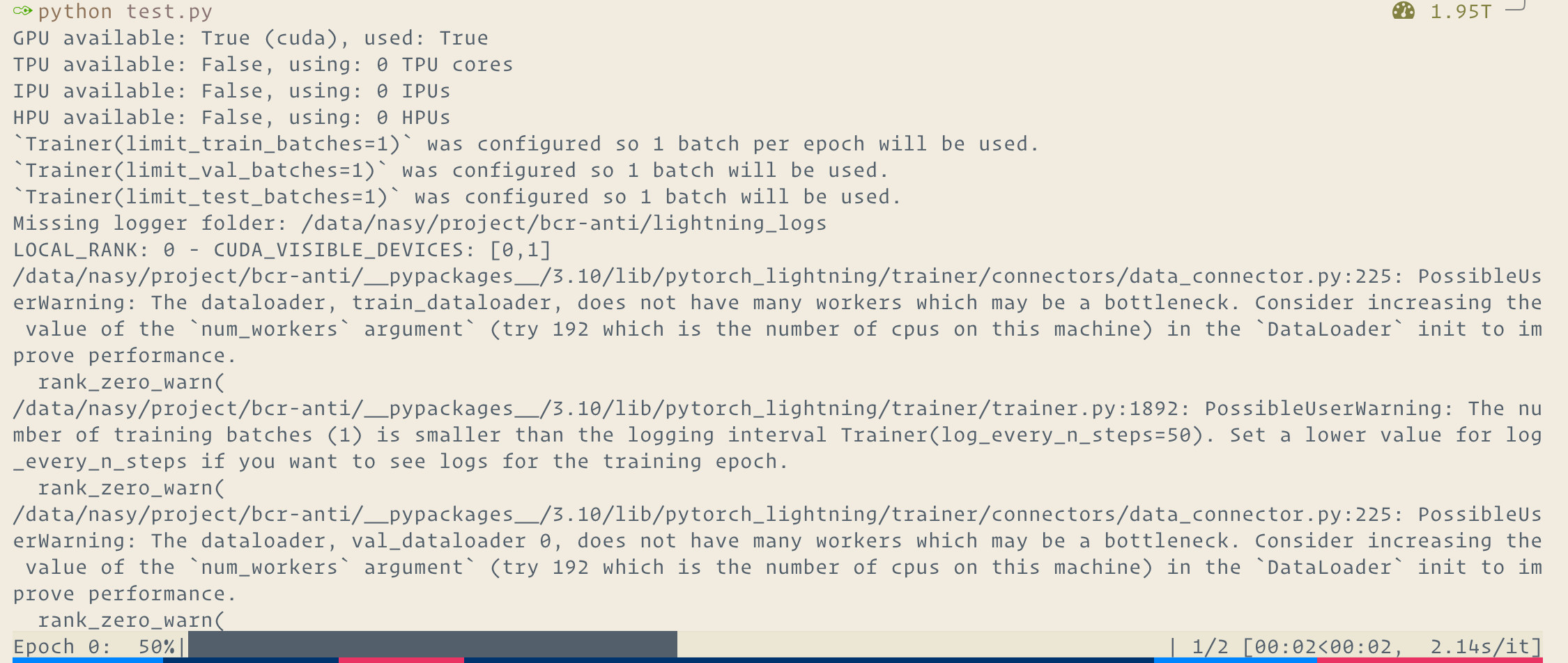
But, if I run with pure Torch, it works:

To Reproduce
The test file for pl:
import os
import torch
from torch.utils.data import DataLoader, Dataset
from pytorch_lightning import LightningModule, Trainer
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
class BoringModel(LightningModule):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(32, 2)
def forward(self, x):
return self.layer(x)
def training_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("train_loss", loss)
return {"loss": loss}
def validation_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("valid_loss", loss)
def test_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("test_loss", loss)
def configure_optimizers(self):
return torch.optim.SGD(self.layer.parameters(), lr=0.1)
def run():
train_data = DataLoader(RandomDataset(32, 64), batch_size=2)
val_data = DataLoader(RandomDataset(32, 64), batch_size=2)
test_data = DataLoader(RandomDataset(32, 64), batch_size=2)
model = BoringModel()
trainer = Trainer(
default_root_dir=os.getcwd(),
accelerator="cuda",
strategy="ddp",
limit_train_batches=1,
limit_val_batches=1,
limit_test_batches=1,
num_sanity_val_steps=0,
max_epochs=1,
enable_model_summary=False,
)
trainer.fit(model, train_dataloaders=train_data, val_dataloaders=val_data)
trainer.test(model, dataloaders=test_data)
if __name__ == "__main__":
run()And the test2 file for pure torch:
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# Parameters and DataLoaders
input_size = 5
output_size = 2
batch_size = 30
data_size = 100
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
device = "cuda"
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
model.to(device)
for data in rand_loader:
input = data.to(device)
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())Expected behavior
Run train, val, and test.
Environment
Details
- CUDA:
- GPU:
- NVIDIA A100 80GB PCIe
- NVIDIA A100 80GB PCIe
- available: True
- version: 11.6 - Lightning:
- pytorch-lightning: 1.7.4
- torch: 1.12.1+cu116
- torchmetrics: 0.9.3
- torchvision: 0.13.1+cu116 - Packages:
- absl-py: 1.2.0
- aiohttp: 3.8.1
- aiosignal: 1.2.0
- anyio: 3.6.1
- appdirs: 1.4.4
- astor: 0.8.1
- asttokens: 2.0.8
- async-timeout: 4.0.2
- attrs: 22.1.0
- backcall: 0.2.0
- bandit: 1.7.4
- beautifulsoup4: 4.11.1
- beniget: 0.4.1
- better-exceptions: 0.3.3
- black: 22.8.0
- blinker: 1.5
- cachecontrol: 0.12.11
- cachetools: 5.2.0
- certifi: 2022.6.15
- charset-normalizer: 2.1.1
- click: 8.1.3
- colorful: 0.5.4
- commonmark: 0.9.1
- cycler: 0.11.0
- cython: 0.29.32
- darglint: 1.8.1
- decorator: 5.1.1
- distlib: 0.3.6
- docopt: 0.6.2
- docutils: 0.19
- dynaconf: 3.1.9
- eradicate: 2.1.0
- executing: 1.0.0
- filelock: 3.8.0
- findpython: 0.2.1
- flake8: 4.0.1
- flake8-bandit: 3.0.0
- flake8-broken-line: 0.4.0
- flake8-bugbear: 22.8.23
- flake8-commas: 2.1.0
- flake8-comprehensions: 3.10.0
- flake8-debugger: 4.1.2
- flake8-docstrings: 1.6.0
- flake8-eradicate: 1.3.0
- flake8-isort: 4.2.0
- flake8-polyfill: 1.0.2
- flake8-quotes: 3.3.1
- flake8-rst-docstrings: 0.2.7
- flake8-string-format: 0.3.0
- fonttools: 4.37.1
- frozenlist: 1.3.1
- fsspec: 2022.8.2
- gast: 0.5.3
- gitdb: 4.0.9
- gitpython: 3.1.27
- google-auth: 2.11.0
- google-auth-oauthlib: 0.4.6
- grpcio: 1.49.0rc3
- h11: 0.12.0
- httpcore: 0.15.0
- httpx: 0.23.0
- idna: 3.3
- immutables: 0.18
- installer: 0.5.1
- ipdb: 0.13.9
- ipython: 8.4.0
- isort: 5.10.1
- jedi: 0.18.1
- joblib: 1.1.0
- jupyter-qtconsole-colorschemes: 0.8.1
- kiwisolver: 1.4.4
- lockfile: 0.12.2
- markdown: 3.4.1
- markupsafe: 2.1.1
- matplotlib: 3.5.3
- matplotlib-inline: 0.1.6
- mccabe: 0.6.1
- more-itertools: 8.14.0
- mpmath: 1.2.1
- msgpack: 1.0.4
- multidict: 6.0.2
- mypy: 0.971
- mypy-extensions: 0.4.3
- naipyext: 0.7.0
- numpy: 1.23.2
- oauthlib: 3.2.0
- packaging: 21.3
- pandas: 1.4.4
- parso: 0.8.3
- pathspec: 0.10.1
- pbr: 5.10.0
- pdir2: 0.3.5
- pdm: 2.1.3
- pdm-pep517: 1.0.4
- pendulum: 0.4
- pep517: 0.13.0
- pep8-naming: 0.12.1
- pexpect: 4.8.0
- pickleshare: 0.7.5
- pillow: 9.2.0
- platformdirs: 2.5.2
- ply: 3.11
- prettyprinter: 0.18.0
- prompt-toolkit: 3.0.31
- protobuf: 3.19.4
- ptipython: 1.0.1
- ptpython: 3.0.20
- ptyprocess: 0.7.0
- pure-eval: 0.2.2
- pyasn1: 0.5.0rc2
- pyasn1-modules: 0.3.0rc1
- pybind11: 2.10.0
- pycodestyle: 2.8.0
- pydeprecate: 0.3.2
- pydocstyle: 6.1.1
- pyflakes: 2.4.0
- pygments: 2.13.0
- pyparsing: 3.0.9
- python-dateutil: 2.8.2
- python-dotenv: 0.21.0
- pythran: 0.11.0
- pytorch-lightning: 1.7.4
- pytz: 2022.2.1
- pytz-deprecation-shim: 0.1.0.post0
- pyyaml: 6.0
- requests: 2.28.1
- requests-oauthlib: 1.3.1
- requests-toolbelt: 0.9.1
- resolvelib: 0.8.1
- restructuredtext-lint: 1.4.0
- rfc3986: 1.5.0
- rich: 12.5.1
- rsa: 4.9
- scikit-learn: 1.1.2
- scipy: 1.9.1
- seaborn: 0.11.2
- setuptools: 65.3.0
- shellingham: 1.5.0
- six: 1.16.0
- smile-config: 0.9.1
- smmap: 5.0.0
- sniffio: 1.3.0
- snowballstemmer: 2.2.0
- soupsieve: 2.3.2.post1
- stack-data: 0.5.0
- stevedore: 4.0.0
- sympy: 1.11.1
- tensorboard: 2.10.0
- tensorboard-data-server: 0.6.1
- tensorboard-plugin-wit: 1.8.1
- threadpoolctl: 3.1.0
- toml: 0.10.2
- tomli: 2.0.1
- tomlkit: 0.11.4
- torch: 1.12.1+cu116 - System:
- OS: Linux
- architecture:
- 64bit
- ELF
- processor: x86_64
- python: 3.10.6
- version: Error if dataset size = 1 batch. #141-Ubuntu SMP Wed Aug 10 13:42:03 UTC 2022