In multinode training with ddp each node duplicates logs and has node_rank=0 #13639
Description
🐛 Bug
When training using ddp in a multi-node environment with seed_everything(workers=True) there are identical loss values logged on each node. For example this occurs in a 3 node environment with limit_val_batches=2 (logged via mlflow):
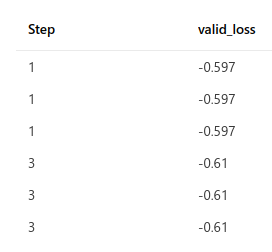
The NODE_RANK of each node is 0 (which shouldn't be the case) and identical loss values also appear in each node's process when printed to the screen so it appears each node is using the same data in the same order. One fix I attempted was to set NODE_RANK to OMPI_COMM_WORLD_RANK, but this resulted in the job hanging or crashing.
To Reproduce
Download the two python scripts below (edit as needed to run on a multinode multi-gpu Azure cluster) and then run python submit_job.py. AzureML is used to submit the job with an MPIConfiguration.
submit_job.py:
import os
from azureml.core.runconfig import PyTorchConfiguration, MpiConfiguration
from azureml.core import Environment, Workspace, ScriptRunConfig, Experiment
from azureml.core.authentication import ServicePrincipalAuthentication
experiment_name = "XXXXXXXXX"
environment_name = "XXXXXXXX"
cluster_name="XXXXXXX"
node_count=3
environment_version="XXXXXXX"
command="; ".join([
"python -m pip freeze",
"wget https://raw.githubusercontent.com/Lightning-AI/lightning/master/requirements/collect_env_details.py",
"python collect_env_details.py",
"python logging_reprex.py"
])
print(command)
ws = Workspace.get(
name="XXXXXXXXX",
resource_group="XXXXXXXXXX",
subscription_id=os.environ["AZURE_SUBSCRIPTION_ID"],
auth= ServicePrincipalAuthentication(
tenant_id=os.environ.get("AZURE_TENANT_ID"),
service_principal_id=os.environ.get("AZURE_CLIENT_ID"),
service_principal_password=os.environ.get("AZURE_CLIENT_SECRET")
)
)
compute_target=ws.compute_targets[cluster_name]
env = Environment.get(
workspace = ws,
name = environment_name,
version = environment_version
)
print(env)
print(env.get_image_details(ws))
job_config = MpiConfiguration(node_count=node_count, process_count_per_node=1)
src = ScriptRunConfig(
source_directory = ".",
command=command,
compute_target = compute_target,
environment = env,
distributed_job_config = job_config
)
# Submit job
run = Experiment(ws, experiment_name).submit(src)logging_reprex.py:
import numpy as np # fix for https://github.com/pytorch/pytorch/issues/37377
import torch, os, logging, sys
from torch.utils.data import DataLoader, Dataset
#from deepspeed.ops.adam import FusedAdam
from azureml.core import Run, Workspace
from pytorch_lightning import LightningModule, Trainer, LightningDataModule, seed_everything
from pytorch_lightning.loggers import MLFlowLogger
divider_str="-"*40
def get_env_display_text(var_name):
var_value = os.environ.get(var_name, "")
return f"{var_name} = {var_value}"
def display_environment(header='Environmental variables'):
"""
Print a few environment variables of note
"""
variable_names = [
"PL_GLOBAL_SEED",
"PL_SEED_WORKERS",
"AZ_BATCH_MASTER_NODE",
"AZ_BATCHAI_MPI_MASTER_NODE",
"MASTER_ADDR",
"MASTER_ADDRESS",
"MASTER_PORT",
"RANK",
"NODE_RANK",
"LOCAL_RANK",
"GLOBAL_RANK",
"WORLD_SIZE",
"NCCL_SOCKET_IFNAME",
"OMPI_COMM_WORLD_RANK",
"OMPI_COMM_WORLD_LOCAL_RANK",
"OMPI_COMM_WORLD_SIZE",
"OMPI_COMM_WORLD_LOCAL_SIZE"
]
var_text = "\n".join([get_env_display_text(var) for var in variable_names])
print(f"\n{header}:\n{divider_str}\n{var_text}\n{divider_str}\n")
def get_run():
"""
Returns active run azureml object
"""
run = Run.get_context()
return run
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
class BoringModel(LightningModule):
def __init__(self):
super().__init__()
self.save_hyperparameters()
self.model = torch.nn.Linear(32, 2)
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("train_loss", loss, on_step=True, on_epoch=True)
return {"loss": loss}
def validation_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("valid_loss", loss)
print(f"""self.global_step: {self.global_step}
gpu #: {torch.cuda.current_device()}
batch_idx: {batch_idx}
loss: {loss}
""")
def configure_optimizers(self):
return torch.optim.AdamW(self.model.parameters())
#return FusedAdam(self.model.parameters())
def setup(self, stage=None) -> None:
# prevents hanging
if stage != "fit":
return
display_environment(f"LightningModule setup(stage={stage})")
class DataModule(LightningDataModule):
def __init__(self):
super().__init__()
self.num_workers = os.cpu_count()
print(f"num_workers set to {self.num_workers}")
def setup(self, stage=None) -> None:
display_environment(f"DataModule setup(stage={stage})")
self._dataloader = DataLoader(
RandomDataset(32, 64),
num_workers=self.num_workers,
batch_size=1,
pin_memory=True
)
def train_dataloader(self):
return self._dataloader
def test_dataloader(self):
return self._dataloader
def val_dataloader(self):
return self._dataloader
if __name__ == "__main__":
# Toggle comment here to make logged loss values identical (uncommented) or unique (commented)
seed_everything(102938, workers = True)
display_environment("__main__")
model = BoringModel()
dm = DataModule()
# If running on azure, get the active tracking uri and run id
# else, use the workspace to get a uri
active_run = get_run()
offline = False
try:
print(active_run.experiment)
except:
offline = True
if offline:
print("Running offline...")
run_id = None
ws = Workspace.get(
subscription_id=os.environ.get("AZURE_SUBSCRIPTION_ID"),
resource_group="XXXXXXX",
name="XXXXXXXX",
)
tracking_uri = ws.get_mlflow_tracking_uri()
else:
tracking_uri =active_run.experiment.workspace.get_mlflow_tracking_uri()
run_id = active_run.id
logger = MLFlowLogger(
experiment_name='reprex',
tracking_uri=tracking_uri,
run_id=run_id
)
trainer = Trainer(
accelerator='gpu',
auto_select_gpus=True,
limit_train_batches=2,
limit_val_batches=2,
log_every_n_steps=1,
logger=logger,
enable_checkpointing=False,
num_sanity_val_steps=0,
max_epochs=2,
enable_model_summary=False,
strategy="ddp",
precision=16
)
trainer.fit(model, datamodule=dm)Expected behavior
Nodes should load different data from their dataloaders and should not duplicate logged loss values.
Environment
- 3 node Azure compute cluster
- Each node has 2x V100 GPUs and the base docker image for the environment is
mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.3-cudnn8-ubuntu20.04
* CUDA:
- GPU:
- Tesla V100-PCIE-16GB
- Tesla V100-PCIE-16GB
- available: True
- version: 11.3
* Packages:
- numpy: 1.22.3
- pyTorch_debug: False
- pyTorch_version: 1.11.0
- pytorch-lightning: 1.6.4
- tqdm: 4.64.0
* System:
- OS: Linux
- architecture:
- 64bit
- ELF
- processor: x86_64
- python: 3.8.13
- version: #38-Ubuntu SMP Sun Mar 22 21:27:21 UTC 2020
Environmental variables are printed to the log in the python script at various points in the process. Below are the values of these environmental variables on each node before the LightningModule and LightningDataModule objects are initiated (ie. the display_environment("__main__") call in the script above).
Node 1
__main__:
----------------------------------------
PL_GLOBAL_SEED = 102938
PL_SEED_WORKERS = 1
MASTER_ADDR = 127.0.0.1
MASTER_ADDRESS =
MASTER_PORT = 38581
RANK =
NODE_RANK = 0
LOCAL_RANK = 1
GLOBAL_RANK =
WORLD_SIZE = 2
NCCL_SOCKET_IFNAME = eth0
OMPI_COMM_WORLD_RANK = 0
OMPI_COMM_WORLD_LOCAL_RANK = 0
OMPI_COMM_WORLD_SIZE = 3
OMPI_COMM_WORLD_LOCAL_SIZE = 1
----------------------------------------Node 2
__main__:
----------------------------------------
PL_GLOBAL_SEED = 102938
PL_SEED_WORKERS = 1
MASTER_ADDR = 127.0.0.1
MASTER_ADDRESS =
MASTER_PORT = 57987
RANK =
NODE_RANK = 0
LOCAL_RANK = 1
GLOBAL_RANK =
WORLD_SIZE = 2
NCCL_SOCKET_IFNAME = eth0
OMPI_COMM_WORLD_RANK = 1
OMPI_COMM_WORLD_LOCAL_RANK = 0
OMPI_COMM_WORLD_SIZE = 3
OMPI_COMM_WORLD_LOCAL_SIZE = 1
----------------------------------------Node 3
__main__:
----------------------------------------
PL_GLOBAL_SEED = 102938
PL_SEED_WORKERS = 1
MASTER_ADDR = 127.0.0.1
MASTER_ADDRESS =
MASTER_PORT = 46819
RANK =
NODE_RANK = 0
LOCAL_RANK = 1
GLOBAL_RANK =
WORLD_SIZE = 2
NCCL_SOCKET_IFNAME = eth0
OMPI_COMM_WORLD_RANK = 2
OMPI_COMM_WORLD_LOCAL_RANK = 0
OMPI_COMM_WORLD_SIZE = 3
OMPI_COMM_WORLD_LOCAL_SIZE = 1
----------------------------------------cc @Borda @awaelchli @rohitgr7 @akihironitta @justusschock @kaushikb11 @ananthsub @carmocca @edward-io @kamil-kaczmarek @Raalsky @Blaizzy