diff --git a/.github/workflows/build_documentation.yml b/.github/workflows/build_documentation.yml
index 982795752..ddd416799 100644
--- a/.github/workflows/build_documentation.yml
+++ b/.github/workflows/build_documentation.yml
@@ -14,6 +14,6 @@ jobs:
package: course
path_to_docs: course/chapters/
additional_args: --not_python_module
- languages: ar bn de en es fa fr gj he hi id it ja ko ne pl pt ru rum th tr vi zh-CN zh-TW
+ languages: ar bn de en es fa fr gj he hi id it ja ko ne pl pt ru rum te th tr vi zh-CN zh-TW
secrets:
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
diff --git a/.github/workflows/build_pr_documentation.yml b/.github/workflows/build_pr_documentation.yml
index 53541f297..43664e711 100644
--- a/.github/workflows/build_pr_documentation.yml
+++ b/.github/workflows/build_pr_documentation.yml
@@ -16,4 +16,4 @@ jobs:
package: course
path_to_docs: course/chapters/
additional_args: --not_python_module
- languages: ar bn de en es fa fr gj he hi id it ja ko ne pl pt ru rum th tr vi zh-CN zh-TW
+ languages: ar bn de en es fa fr gj he hi id it ja ko ne pl pt ru rum te th tr vi zh-CN zh-TW
diff --git a/README.md b/README.md
index e8b6311fb..07dadca56 100644
--- a/README.md
+++ b/README.md
@@ -21,12 +21,13 @@ This repo contains the content that's used to create the **[Hugging Face course]
| [Korean](https://huggingface.co/course/ko/chapter1/1) (WIP) | [`chapters/ko`](https://github.com/huggingface/course/tree/main/chapters/ko) | [@Doohae](https://github.com/Doohae), [@wonhyeongseo](https://github.com/wonhyeongseo), [@dlfrnaos19](https://github.com/dlfrnaos19), [@nsbg](https://github.com/nsbg) |
| [Portuguese](https://huggingface.co/course/pt/chapter1/1) (WIP) | [`chapters/pt`](https://github.com/huggingface/course/tree/main/chapters/pt) | [@johnnv1](https://github.com/johnnv1), [@victorescosta](https://github.com/victorescosta), [@LincolnVS](https://github.com/LincolnVS) |
| [Russian](https://huggingface.co/course/ru/chapter1/1) (WIP) | [`chapters/ru`](https://github.com/huggingface/course/tree/main/chapters/ru) | [@pdumin](https://github.com/pdumin), [@svv73](https://github.com/svv73), [@blademoon](https://github.com/blademoon) |
+| [Telugu]( https://huggingface.co/course/te/chapter0/1 ) (WIP) | [`chapters/te`](https://github.com/huggingface/course/tree/main/chapters/te) | [@Ajey95](https://github.com/Ajey95)
| [Thai](https://huggingface.co/course/th/chapter1/1) (WIP) | [`chapters/th`](https://github.com/huggingface/course/tree/main/chapters/th) | [@peeraponw](https://github.com/peeraponw), [@a-krirk](https://github.com/a-krirk), [@jomariya23156](https://github.com/jomariya23156), [@ckingkan](https://github.com/ckingkan) |
| [Turkish](https://huggingface.co/course/tr/chapter1/1) (WIP) | [`chapters/tr`](https://github.com/huggingface/course/tree/main/chapters/tr) | [@tanersekmen](https://github.com/tanersekmen), [@mertbozkir](https://github.com/mertbozkir), [@ftarlaci](https://github.com/ftarlaci), [@akkasayaz](https://github.com/akkasayaz) |
| [Vietnamese](https://huggingface.co/course/vi/chapter1/1) | [`chapters/vi`](https://github.com/huggingface/course/tree/main/chapters/vi) | [@honghanhh](https://github.com/honghanhh) |
| [Chinese (simplified)](https://huggingface.co/course/zh-CN/chapter1/1) | [`chapters/zh-CN`](https://github.com/huggingface/course/tree/main/chapters/zh-CN) | [@zhlhyx](https://github.com/zhlhyx), [petrichor1122](https://github.com/petrichor1122), [@1375626371](https://github.com/1375626371) |
| [Chinese (traditional)](https://huggingface.co/course/zh-TW/chapter1/1) (WIP) | [`chapters/zh-TW`](https://github.com/huggingface/course/tree/main/chapters/zh-TW) | [@davidpeng86](https://github.com/davidpeng86) |
-
+| [Romanian](https://huggingface.co/course/rum/chapter1/1) (WIP) | [`chapters/rum`](https://github.com/huggingface/course/tree/main/chapters/rum) | [@Sigmoid](https://github.com/SigmoidAI), [@eduard-balamatiuc](https://github.com/eduard-balamatiuc), [@FriptuLudmila](https://github.com/FriptuLudmila), [@tokyo-s](https://github.com/tokyo-s), [@hbkdesign](https://github.com/hbkdesign) |
### Translating the course into your language
diff --git a/chapters/en/_toctree.yml b/chapters/en/_toctree.yml
index 7f8d105ca..9a30743e0 100644
--- a/chapters/en/_toctree.yml
+++ b/chapters/en/_toctree.yml
@@ -14,7 +14,7 @@
- local: chapter1/4
title: How do Transformers work?
- local: chapter1/5
- title: How 🤗 Transformers solve tasks
+ title: Solving Tasks with Transformers
- local: chapter1/6
title: Transformer Architectures
- local: chapter1/7
@@ -46,6 +46,8 @@
- local: chapter2/7
title: Basic usage completed!
- local: chapter2/8
+ title: Optimized Inference Deployment
+ - local: chapter2/9
title: End-of-chapter quiz
quiz: 2
diff --git a/chapters/en/chapter12/3a.mdx b/chapters/en/chapter12/3a.mdx
index b4effb193..6235680e4 100644
--- a/chapters/en/chapter12/3a.mdx
+++ b/chapters/en/chapter12/3a.mdx
@@ -10,11 +10,11 @@ Let's deepen our understanding of GRPO so that we can improve our model's traini
GRPO directly evaluates the model-generated responses by comparing them within groups of generation to optimize policy model, instead of training a separate value model (Critic). This approach leads to significant reduction in computational cost!
-GRPO can be applied to any verifiable task where the correctness of the response can be determined. For instance, in math reasoning, the correctness of the response can be easily verified by comparing it to the ground truth.
+GRPO can be applied to any verifiable task where the correctness of the response can be determined. For instance, in math reasoning, the correctness of the response can be easily verified by comparing it to the ground truth.
Before diving into the technical details, let's visualize how GRPO works at a high level:
-
+
Now that we have a visual overview, let's break down how GRPO works step by step.
@@ -28,14 +28,19 @@ Let's walk through each step of the algorithm in detail:
The first step is to generate multiple possible answers for each question. This creates a diverse set of outputs that can be compared against each other.
-For each question $q$, the model will generate $G$ outputs (group size) from the trained policy:{ ${o_1, o_2, o_3, \dots, o_G}\pi_{\theta_{\text{old}}}$ }, $G=8$ where each $o_i$ represents one completion from the model.
+For each question \\( q \\), the model will generate \\( G \\) outputs (group size) from the trained policy: { \\( {o_1, o_2, o_3, \dots, o_G}\pi_{\theta_{\text{old}}} \\) }, \\( G=8 \\) where each \\( o_i \\) represents one completion from the model.
-#### Example:
+#### Example
To make this concrete, let's look at a simple arithmetic problem:
-- **Question** $q$ : $\text{Calculate}\space2 + 2 \times 6$
-- **Outputs** $(G = 8)$: $\{o_1:14 \text{ (correct)}, o_2:16 \text{ (wrong)}, o_3:10 \text{ (wrong)}, \ldots, o_8:14 \text{ (correct)}\}$
+**Question**
+
+\\( q \\) : \\( \text{Calculate}\space2 + 2 \times 6 \\)
+
+**Outputs**
+
+\\( (G = 8) \\): \\( \{o_1:14 \text{ (correct)}, o_2:16 \text{ (wrong)}, o_3:10 \text{ (wrong)}, \ldots, o_8:14 \text{ (correct)}\} \\)
Notice how some of the generated answers are correct (14) while others are wrong (16 or 10). This diversity is crucial for the next step.
@@ -43,34 +48,36 @@ Notice how some of the generated answers are correct (14) while others are wrong
Once we have multiple responses, we need a way to determine which ones are better than others. This is where the advantage calculation comes in.
-#### Reward Distribution:
+#### Reward Distribution
First, we assign a reward score to each generated response. In this example, we'll use a reward model, but as we learnt in the previous section, we can use any reward returning function.
-Assign a RM score to each of the generated responses based on the correctness $r_i$ *(e.g. 1 for correct response, 0 for wrong response)* then for each of the $r_i$ calculate the following Advantage value
+Assign a RM score to each of the generated responses based on the correctness \\( r_i \\) *(e.g. 1 for correct response, 0 for wrong response)* then for each of the \\( r_i \\) calculate the following Advantage value.
-#### Advantage Value Formula:
+#### Advantage Value Formula
The key insight of GRPO is that we don't need absolute measures of quality - we can compare outputs within the same group. This is done using standardization:
$$A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \ldots, r_G\})}{\text{std}(\{r_1, r_2, \ldots, r_G\})}$$
-#### Example:
+#### Example
Continuing with our arithmetic example for the same example above, imagine we have 8 responses, 4 of which is correct and the rest wrong, therefore;
-- Group Average: $mean(r_i) = 0.5$
-- Std: $std(r_i) = 0.53$
-- Advantage Value:
- - Correct response: $A_i = \frac{1 - 0.5}{0.53}= 0.94$
- - Wrong response: $A_i = \frac{0 - 0.5}{0.53}= -0.94$
-#### Interpretation:
+| Metric | Value |
+|--------|-------|
+| Group Average | \\( mean(r_i) = 0.5 \\) |
+| Standard Deviation | \\( std(r_i) = 0.53 \\) |
+| Advantage Value (Correct response) | \\( A_i = \frac{1 - 0.5}{0.53}= 0.94 \\) |
+| Advantage Value (Wrong response) | \\( A_i = \frac{0 - 0.5}{0.53}= -0.94 \\) |
+
+#### Interpretation
Now that we have calculated the advantage values, let's understand what they mean:
-This standardization (i.e. $A_i$ weighting) allows the model to assess each response's relative performance, guiding the optimization process to favour responses that are better than average (high reward) and discourage those that are worse. For instance if $A_i > 0$, then the $o_i$ is better response than the average level within its group; and if $A_i < 0$, then the $o_i$ then the quality of the response is less than the average (i.e. poor quality/performance).
+This standardization (i.e. \\( A_i \\) weighting) allows the model to assess each response's relative performance, guiding the optimization process to favorable responses that are better than average (high reward) and discourage those that are worse. For instance if \\( A_i > 0 \\), then the \\( o_i \\) is better response than the average level within its group; and if \\( A_i < 0 \\), then the \\( o_i \\) then the quality of the response is less than the average (i.e. poor quality/performance).
-For the example above, if $A_i = 0.94 \text{(correct output)}$ then during optimization steps its generation probability will be increased.
+For the example above, if \\( A_i = 0.94 \text{(correct output)} \\) then during optimization steps its generation probability will be increased.
With our advantage values calculated, we're now ready to update the policy.
@@ -80,7 +87,7 @@ The final step is to use these advantage values to update our model so that it b
The target function for policy update is:
-$$J_{GRPO}(\theta) = \left[\frac{1}{G} \sum_{i=1}^{G} \min \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} A_i \text{clip}\left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right)\right]- \beta D_{KL}(\pi_{\theta} || \pi_{ref})$$
+$$J_{GRPO}(\theta) = \left[\frac{1}{G} \sum_{i=1}^{G} \min \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} A_i \text{clip}\left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right)\right]- \beta D_{KL}(\pi_{\theta} \|\| \pi_{ref})$$
This formula might look intimidating at first, but it's built from several components that each serve an important purpose. Let's break them down one by one.
@@ -92,13 +99,14 @@ The GRPO update function combines several techniques to ensure stable and effect
The probability ratio is defined as:
-$\left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}\right)$
+\\( \left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}\right) \\)
Intuitively, the formula compares how much the new model's response probability differs from the old model's response probability while incorporating a preference for responses that improve the expected outcome.
-#### Interpretation:
-- If $\text{ratio} > 1$, the new model assigns a higher probability to response $o_i$ than the old model.
-- If $\text{ratio} < 1$, the new model assigns a lower probability to $o_i$
+#### Interpretation
+
+- If \\( \text{ratio} > 1 \\), the new model assigns a higher probability to response \\( o_i \\) than the old model.
+- If \\( \text{ratio} < 1 \\), the new model assigns a lower probability to \\( o_i \\)
This ratio allows us to control how much the model changes at each step, which leads us to the next component.
@@ -106,22 +114,25 @@ This ratio allows us to control how much the model changes at each step, which l
The clipping function is defined as:
-$\text{clip}\left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1 - \epsilon, 1 + \epsilon\right)$
+\\( \text{clip}\left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1 - \epsilon, 1 + \epsilon\right) \\)
-Limit the ratio discussed above to be within $[1 - \epsilon, 1 + \epsilon]$ to avoid/control drastic changes or crazy updates and stepping too far off from the old policy. In other words, it limit how much the probability ratio can increase to help maintaining stability by avoiding updates that push the new model too far from the old one.
+Limit the ratio discussed above to be within \\( [1 - \epsilon, 1 + \epsilon] \\) to avoid/control drastic changes or crazy updates and stepping too far off from the old policy. In other words, it limit how much the probability ratio can increase to help maintaining stability by avoiding updates that push the new model too far from the old one.
+
+#### Example (ε = 0.2)
-#### Example $\space \text{suppose}(\epsilon = 0.2)$
Let's look at two different scenarios to better understand this clipping function:
- **Case 1**: if the new policy has a probability of 0.9 for a specific response and the old policy has a probabiliy of 0.5, it means this response is getting reinforeced by the new policy to have higher probability, but within a controlled limit which is the clipping to tight up its hands to not get drastic
- - $\text{Ratio}: \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} = \frac{0.9}{0.5} = 1.8 → \text{Clip}\space1.2$ (upper bound limit 1.2)
+ - \\( \text{Ratio}: \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} = \frac{0.9}{0.5} = 1.8 → \text{Clip}\space1.2 \\) (upper bound limit 1.2)
- **Case 2**: If the new policy is not in favour of a response (lower probability e.g. 0.2), meaning if the response is not beneficial the increase might be incorrect, and the model would be penalized.
- - $\text{Ratio}: \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} = \frac{0.2}{0.5} = 0.4 →\text{Clip}\space0.8$ (lower bound limit 0.8)
-#### Interpretation:
+ - \\( \text{Ratio}: \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} = \frac{0.2}{0.5} = 0.4 →\text{Clip}\space0.8 \\) (lower bound limit 0.8)
+
+#### Interpretation
+
- The formula encourages the new model to favour responses that the old model underweighted **if they improve the outcome**.
-- If the old model already favoured a response with a high probability, the new model can still reinforce it **but only within a controlled limit $[1 - \epsilon, 1 + \epsilon]$, $\text{(e.g., }\epsilon = 0.2, \space \text{so} \space [0.8-1.2])$**.
+- If the old model already favoured a response with a high probability, the new model can still reinforce it **but only within a controlled limit \\( [1 - \epsilon, 1 + \epsilon] \\), \\( \text{(e.g., }\epsilon = 0.2, \space \text{so} \space [0.8-1.2]) \\)**.
- If the old model overestimated a response that performs poorly, the new model is **discouraged** from maintaining that high probability.
-- Therefore, intuitively, By incorporating the probability ratio, the objective function ensures that updates to the policy are proportional to the advantage $A_i$ while being moderated to prevent drastic changes. T
+- Therefore, intuitively, By incorporating the probability ratio, the objective function ensures that updates to the policy are proportional to the advantage \\( A_i \\) while being moderated to prevent drastic changes. T
While the clipping function helps prevent drastic changes, we need one more safeguard to ensure our model doesn't deviate too far from its original behavior.
@@ -129,33 +140,35 @@ While the clipping function helps prevent drastic changes, we need one more safe
The KL divergence term is:
-$\beta D_{KL}(\pi_{\theta} || \pi_{ref})$
+\\( \beta D_{KL}(\pi_{\theta} \|\| \pi_{ref}) \\)
-In the KL divergence term, the $\pi_{ref}$ is basically the pre-update model's output, `per_token_logps` and $\pi_{\theta}$ is the new model's output, `new_per_token_logps`. Theoretically, KL divergence is minimized to prevent the model from deviating too far from its original behavior during optimization. This helps strike a balance between improving performance based on the reward signal and maintaining coherence. In this context, minimizing KL divergence reduces the risk of the model generating nonsensical text or, in the case of mathematical reasoning, producing extremely incorrect answers.
+In the KL divergence term, the \\( \pi_{ref} \\) is basically the pre-update model's output, `per_token_logps` and \\( \pi_{\theta} \\) is the new model's output, `new_per_token_logps`. Theoretically, KL divergence is minimized to prevent the model from deviating too far from its original behavior during optimization. This helps strike a balance between improving performance based on the reward signal and maintaining coherence. In this context, minimizing KL divergence reduces the risk of the model generating nonsensical text or, in the case of mathematical reasoning, producing extremely incorrect answers.
#### Interpretation
+
- A KL divergence penalty keeps the model's outputs close to its original distribution, preventing extreme shifts.
- Instead of drifting towards completely irrational outputs, the model would refine its understanding while still allowing some exploration
#### Math Definition
+
For those interested in the mathematical details, let's look at the formal definition:
Recall that KL distance is defined as follows:
-$$D_{KL}(P || Q) = \sum_{x \in X} P(x) \log \frac{P(x)}{Q(x)}$$
+$$D_{KL}(P \|\| Q) = \sum_{x \in X} P(x) \log \frac{P(x)}{Q(x)}$$
In RLHF, the two distributions of interest are often the distribution of the new model version, P(x), and a distribution of the reference policy, Q(x).
-#### The Role of $\beta$ Parameter
+#### The Role of β Parameter
-The coefficient $\beta$ controls how strongly we enforce the KL divergence constraint:
+The coefficient \\( \beta \\) controls how strongly we enforce the KL divergence constraint:
-- **Higher $\beta$ (Stronger KL Penalty)**
+- **Higher β (Stronger KL Penalty)**
- More constraint on policy updates. The model remains close to its reference distribution.
- Can slow down adaptation: The model may struggle to explore better responses.
-- **Lower $\beta$ (Weaker KL Penalty)**
+- **Lower β (Weaker KL Penalty)**
- More freedom to update policy: The model can deviate more from the reference.
- Faster adaptation but risk of instability: The model might learn reward-hacking behaviors.
- Over-optimization risk: If the reward model is flawed, the policy might generate nonsensical outputs.
-- **Original** [DeepSeekMath](https://arxiv.org/abs/2402.03300) paper set this $\beta= 0.04$
+- **Original** [DeepSeekMath](https://arxiv.org/abs/2402.03300) paper set this \\( \beta= 0.04 \\)
Now that we understand the components of GRPO, let's see how they work together in a complete example.
@@ -169,9 +182,9 @@ $$\text{Q: Calculate}\space2 + 2 \times 6$$
### Step 1: Group Sampling
-First, we generate multiple responses from our model:
+First, we generate multiple responses from our model.
-Generate $(G = 8)$ responses, $4$ of which are correct answer ($14, \text{reward=} 1$) and $4$ incorrect $\text{(reward= 0)}$, Therefore:
+Generate \\( (G = 8) \\) responses, \\( 4 \\) of which are correct answer (\\( 14, \text{reward=} 1 \\)) and \\( 4 \\) incorrect \\( \text{(reward= 0)} \\), Therefore:
$${o_1:14(correct), o_2:10 (wrong), o_3:16 (wrong), ... o_G:14(correct)}$$
@@ -179,20 +192,20 @@ $${o_1:14(correct), o_2:10 (wrong), o_3:16 (wrong), ... o_G:14(correct)}$$
Next, we calculate the advantage values to determine which responses are better than average:
-- Group Average:
-$$mean(r_i) = 0.5$$
-- Std: $$std(r_i) = 0.53$$
-- Advantage Value:
- - Correct response: $A_i = \frac{1 - 0.5}{0.53}= 0.94$
- - Wrong response: $A_i = \frac{0 - 0.5}{0.53}= -0.94$
+| Statistic | Value |
+|-----------|-------|
+| Group Average | \\( mean(r_i) = 0.5 \\) |
+| Standard Deviation | \\( std(r_i) = 0.53 \\) |
+| Advantage Value (Correct response) | \\( A_i = \frac{1 - 0.5}{0.53}= 0.94 \\) |
+| Advantage Value (Wrong response) | \\( A_i = \frac{0 - 0.5}{0.53}= -0.94 \\) |
### Step 3: Policy Update
Finally, we update our model to reinforce the correct responses:
-- Assuming the probability of old policy ($\pi_{\theta_{old}}$) for a correct output $o_1$ is $0.5$ and the new policy increases it to $0.7$ then:
+- Assuming the probability of old policy (\\( \pi_{\theta_{old}} \\)) for a correct output \\( o_1 \\) is \\( 0.5 \\) and the new policy increases it to \\( 0.7 \\) then:
$$\text{Ratio}: \frac{0.7}{0.5} = 1.4 →\text{after Clip}\space1.2 \space (\epsilon = 0.2)$$
-- Then when the target function is re-weighted, the model tends to reinforce the generation of correct output, and the $\text{KL Divergence}$ limits the deviation from the reference policy.
+- Then when the target function is re-weighted, the model tends to reinforce the generation of correct output, and the \\( \text{KL Divergence} \\) limits the deviation from the reference policy.
With the theoretical understanding in place, let's see how GRPO can be implemented in code.
diff --git a/chapters/en/chapter12/img/1.png b/chapters/en/chapter12/img/1.png
deleted file mode 100644
index a53e8a186..000000000
Binary files a/chapters/en/chapter12/img/1.png and /dev/null differ
diff --git a/chapters/en/chapter12/img/2.jpg b/chapters/en/chapter12/img/2.jpg
deleted file mode 100644
index d1fd22662..000000000
Binary files a/chapters/en/chapter12/img/2.jpg and /dev/null differ
diff --git a/chapters/en/chapter2/1.mdx b/chapters/en/chapter2/1.mdx
index 16347ca94..70e290a9d 100644
--- a/chapters/en/chapter2/1.mdx
+++ b/chapters/en/chapter2/1.mdx
@@ -10,7 +10,7 @@ As you saw in [Chapter 1](/course/chapter1), Transformer models are usually very
The 🤗 Transformers library was created to solve this problem. Its goal is to provide a single API through which any Transformer model can be loaded, trained, and saved. The library's main features are:
- **Ease of use**: Downloading, loading, and using a state-of-the-art NLP model for inference can be done in just two lines of code.
-- **Flexibility**: At their core, all models are simple PyTorch `nn.Module` or TensorFlow `tf.keras.Model` classes and can be handled like any other models in their respective machine learning (ML) frameworks.
+- **Flexibility**: At their core, all models are simple PyTorch `nn.Module` classes and can be handled like any other models in their respective machine learning (ML) frameworks.
- **Simplicity**: Hardly any abstractions are made across the library. The "All in one file" is a core concept: a model's forward pass is entirely defined in a single file, so that the code itself is understandable and hackable.
This last feature makes 🤗 Transformers quite different from other ML libraries. The models are not built on modules
diff --git a/chapters/en/chapter2/2.mdx b/chapters/en/chapter2/2.mdx
index 2a35669d7..205e07e51 100644
--- a/chapters/en/chapter2/2.mdx
+++ b/chapters/en/chapter2/2.mdx
@@ -2,8 +2,6 @@
# Behind the pipeline[[behind-the-pipeline]]
-{#if fw === 'pt'}
-
-{:else}
-
-
-
-{/if}
-
-
-This is the first section where the content is slightly different depending on whether you use PyTorch or TensorFlow. Toggle the switch on top of the title to select the platform you prefer!
-
-
-{#if fw === 'pt'}
-{:else}
-
-{/if}
Let's start with a complete example, taking a look at what happened behind the scenes when we executed the following code in [Chapter 1](/course/chapter1):
@@ -83,11 +62,10 @@ tokenizer = AutoTokenizer.from_pretrained(checkpoint)
Once we have the tokenizer, we can directly pass our sentences to it and we'll get back a dictionary that's ready to feed to our model! The only thing left to do is to convert the list of input IDs to tensors.
-You can use 🤗 Transformers without having to worry about which ML framework is used as a backend; it might be PyTorch or TensorFlow, or Flax for some models. However, Transformer models only accept *tensors* as input. If this is your first time hearing about tensors, you can think of them as NumPy arrays instead. A NumPy array can be a scalar (0D), a vector (1D), a matrix (2D), or have more dimensions. It's effectively a tensor; other ML frameworks' tensors behave similarly, and are usually as simple to instantiate as NumPy arrays.
+You can use 🤗 Transformers without having to worry about which ML framework is used as a backend; it might be PyTorch or Flax for some models. However, Transformer models only accept *tensors* as input. If this is your first time hearing about tensors, you can think of them as NumPy arrays instead. A NumPy array can be a scalar (0D), a vector (1D), a matrix (2D), or have more dimensions. It's effectively a tensor; other ML frameworks' tensors behave similarly, and are usually as simple to instantiate as NumPy arrays.
-To specify the type of tensors we want to get back (PyTorch, TensorFlow, or plain NumPy), we use the `return_tensors` argument:
+To specify the type of tensors we want to get back (PyTorch or plain NumPy), we use the `return_tensors` argument:
-{#if fw === 'pt'}
```python
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
@@ -96,21 +74,9 @@ raw_inputs = [
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
```
-{:else}
-```python
-raw_inputs = [
- "I've been waiting for a HuggingFace course my whole life.",
- "I hate this so much!",
-]
-inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="tf")
-print(inputs)
-```
-{/if}
Don't worry about padding and truncation just yet; we'll explain those later. The main things to remember here are that you can pass one sentence or a list of sentences, as well as specifying the type of tensors you want to get back (if no type is passed, you will get a list of lists as a result).
-{#if fw === 'pt'}
-
Here's what the results look like as PyTorch tensors:
```python out
@@ -125,31 +91,11 @@ Here's what the results look like as PyTorch tensors:
])
}
```
-{:else}
-
-Here's what the results look like as TensorFlow tensors:
-
-```python out
-{
- 'input_ids': ,
- 'attention_mask':
-}
-```
-{/if}
The output itself is a dictionary containing two keys, `input_ids` and `attention_mask`. `input_ids` contains two rows of integers (one for each sentence) that are the unique identifiers of the tokens in each sentence. We'll explain what the `attention_mask` is later in this chapter.
## Going through the model[[going-through-the-model]]
-{#if fw === 'pt'}
We can download our pretrained model the same way we did with our tokenizer. 🤗 Transformers provides an `AutoModel` class which also has a `from_pretrained()` method:
```python
@@ -158,16 +104,6 @@ from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
```
-{:else}
-We can download our pretrained model the same way we did with our tokenizer. 🤗 Transformers provides an `TFAutoModel` class which also has a `from_pretrained` method:
-
-```python
-from transformers import TFAutoModel
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-model = TFAutoModel.from_pretrained(checkpoint)
-```
-{/if}
In this code snippet, we have downloaded the same checkpoint we used in our pipeline before (it should actually have been cached already) and instantiated a model with it.
@@ -189,7 +125,6 @@ It is said to be "high dimensional" because of the last value. The hidden size c
We can see this if we feed the inputs we preprocessed to our model:
-{#if fw === 'pt'}
```python
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
@@ -198,16 +133,6 @@ print(outputs.last_hidden_state.shape)
```python out
torch.Size([2, 16, 768])
```
-{:else}
-```py
-outputs = model(inputs)
-print(outputs.last_hidden_state.shape)
-```
-
-```python out
-(2, 16, 768)
-```
-{/if}
Note that the outputs of 🤗 Transformers models behave like `namedtuple`s or dictionaries. You can access the elements by attributes (like we did) or by key (`outputs["last_hidden_state"]`), or even by index if you know exactly where the thing you are looking for is (`outputs[0]`).
@@ -235,7 +160,6 @@ There are many different architectures available in 🤗 Transformers, with each
- `*ForTokenClassification`
- and others 🤗
-{#if fw === 'pt'}
For our example, we will need a model with a sequence classification head (to be able to classify the sentences as positive or negative). So, we won't actually use the `AutoModel` class, but `AutoModelForSequenceClassification`:
```python
@@ -245,17 +169,6 @@ checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
```
-{:else}
-For our example, we will need a model with a sequence classification head (to be able to classify the sentences as positive or negative). So, we won't actually use the `TFAutoModel` class, but `TFAutoModelForSequenceClassification`:
-
-```python
-from transformers import TFAutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
-outputs = model(inputs)
-```
-{/if}
Now if we look at the shape of our outputs, the dimensionality will be much lower: the model head takes as input the high-dimensional vectors we saw before, and outputs vectors containing two values (one per label):
@@ -263,15 +176,9 @@ Now if we look at the shape of our outputs, the dimensionality will be much lowe
print(outputs.logits.shape)
```
-{#if fw === 'pt'}
```python out
torch.Size([2, 2])
```
-{:else}
-```python out
-(2, 2)
-```
-{/if}
Since we have just two sentences and two labels, the result we get from our model is of shape 2 x 2.
@@ -283,49 +190,24 @@ The values we get as output from our model don't necessarily make sense by thems
print(outputs.logits)
```
-{#if fw === 'pt'}
```python out
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=)
```
-{:else}
-```python out
-
-```
-{/if}
Our model predicted `[-1.5607, 1.6123]` for the first sentence and `[ 4.1692, -3.3464]` for the second one. Those are not probabilities but *logits*, the raw, unnormalized scores outputted by the last layer of the model. To be converted to probabilities, they need to go through a [SoftMax](https://en.wikipedia.org/wiki/Softmax_function) layer (all 🤗 Transformers models output the logits, as the loss function for training will generally fuse the last activation function, such as SoftMax, with the actual loss function, such as cross entropy):
-{#if fw === 'pt'}
```py
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
```
-{:else}
-```py
-import tensorflow as tf
-
-predictions = tf.math.softmax(outputs.logits, axis=-1)
-print(predictions)
-```
-{/if}
-{#if fw === 'pt'}
```python out
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=)
```
-{:else}
-```python out
-tf.Tensor(
-[[4.01951671e-02 9.59804833e-01]
- [9.9945587e-01 5.4418424e-04]], shape=(2, 2), dtype=float32)
-```
-{/if}
Now we can see that the model predicted `[0.0402, 0.9598]` for the first sentence and `[0.9995, 0.0005]` for the second one. These are recognizable probability scores.
diff --git a/chapters/en/chapter2/3.mdx b/chapters/en/chapter2/3.mdx
index acc653704..91d3ddd00 100644
--- a/chapters/en/chapter2/3.mdx
+++ b/chapters/en/chapter2/3.mdx
@@ -1,8 +1,6 @@
-# Models[[models]]
-
-{#if fw === 'pt'}
+# Models[[the-models]]
-{:else}
+
-
+In this section, we'll take a closer look at creating and using models. We'll use the `AutoModel` class, which is handy when you want to instantiate any model from a checkpoint.
-{/if}
+## Creating a Transformer[[creating-a-transformer]]
-{#if fw === 'pt'}
-
-{:else}
-
-{/if}
+Let's begin by examining what happens when we instantiate an `AutoModel`:
-{#if fw === 'pt'}
-In this section we'll take a closer look at creating and using a model. We'll use the `AutoModel` class, which is handy when you want to instantiate any model from a checkpoint.
+```py
+from transformers import AutoModel
-The `AutoModel` class and all of its relatives are actually simple wrappers over the wide variety of models available in the library. It's a clever wrapper as it can automatically guess the appropriate model architecture for your checkpoint, and then instantiates a model with this architecture.
+model = AutoModel.from_pretrained("bert-base-cased")
+```
-{:else}
-In this section we'll take a closer look at creating and using a model. We'll use the `TFAutoModel` class, which is handy when you want to instantiate any model from a checkpoint.
+Similar to the tokenizer, the `from_pretrained()` method will download and cache the model data from the Hugging Face Hub. As mentioned previously, the checkpoint name corresponds to a specific model architecture and weights, in this case a BERT model with a basic architecture (12 layers, 768 hidden size, 12 attention heads) and cased inputs (meaning that the uppercase/lowercase distinction is important). There are many checkpoints available on the Hub — you can explore them [here](https://huggingface.co/models).
-The `TFAutoModel` class and all of its relatives are actually simple wrappers over the wide variety of models available in the library. It's a clever wrapper as it can automatically guess the appropriate model architecture for your checkpoint, and then instantiates a model with this architecture.
+The `AutoModel` class and its associates are actually simple wrappers designed to fetch the appropriate model architecture for a given checkpoint. It's an "auto" class meaning it will guess the appropriate model architecture for you and instantiate the correct model class. However, if you know the type of model you want to use, you can use the class that defines its architecture directly:
-{/if}
+```py
+from transformers import BertModel
-However, if you know the type of model you want to use, you can use the class that defines its architecture directly. Let's take a look at how this works with a BERT model.
+model = BertModel.from_pretrained("bert-base-cased")
+```
-## Creating a Transformer[[creating-a-transformer]]
+## Loading and saving[[loading-and-saving]]
-The first thing we'll need to do to initialize a BERT model is load a configuration object:
+Saving a model is as simple as saving a tokenizer. In fact, the models actually have the same `save_pretrained()` method, which saves the model's weights and architecture configuration:
-{#if fw === 'pt'}
```py
-from transformers import BertConfig, BertModel
+model.save_pretrained("directory_on_my_computer")
+```
-# Building the config
-config = BertConfig()
+This will save two files to your disk:
-# Building the model from the config
-model = BertModel(config)
```
-{:else}
+ls directory_on_my_computer
+
+config.json pytorch_model.bin
+```
+
+If you look inside the *config.json* file, you'll see all the necessary attributes needed to build the model architecture. This file also contains some metadata, such as where the checkpoint originated and what 🤗 Transformers version you were using when you last saved the checkpoint.
+
+The *pytorch_model.bin* file is known as the state dictionary; it contains all your model's weights. The two files work together: the configuration file is needed to know about the model architecture, while the model weights are the parameters of the model.
+
+To reuse a saved model, use the `from_pretrained()` method again:
+
```py
-from transformers import BertConfig, TFBertModel
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("directory_on_my_computer")
+```
+
+A wonderful feature of the 🤗 Transformers library is the ability to easily share models and tokenizers with the community. To do this, make sure you have an account on [Hugging Face](https://huggingface.co). If you're using a notebook, you can easily log in with this:
-# Building the config
-config = BertConfig()
+```python
+from huggingface_hub import notebook_login
-# Building the model from the config
-model = TFBertModel(config)
+notebook_login()
```
-{/if}
-The configuration contains many attributes that are used to build the model:
+Otherwise, at your terminal run:
+
+```bash
+huggingface-cli login
+```
+
+Then you can push the model to the Hub with the `push_to_hub()` method:
```py
-print(config)
+model.push_to_hub("my-awesome-model")
```
-```python out
-BertConfig {
- [...]
- "hidden_size": 768,
- "intermediate_size": 3072,
- "max_position_embeddings": 512,
- "num_attention_heads": 12,
- "num_hidden_layers": 12,
- [...]
-}
+This will upload the model files to the Hub, in a repository under your namespace named *my-awesome-model*. Then, anyone can load your model with the `from_pretrained()` method!
+
+```py
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("your-username/my-awesome-model")
```
-While you haven't seen what all of these attributes do yet, you should recognize some of them: the `hidden_size` attribute defines the size of the `hidden_states` vector, and `num_hidden_layers` defines the number of layers the Transformer model has.
+You can do a lot more with the Hub API:
+- Push a model from a local repository
+- Update specific files without re-uploading everything
+- Add model cards to document the model's abilities, limitations, known biases, etc.
-### Different loading methods[[different-loading-methods]]
+See [the documentation](https://huggingface.co/docs/huggingface_hub/how-to-upstream) for a complete tutorial on this, or check out the advanced [Chapter 4](/course/chapter4).
-Creating a model from the default configuration initializes it with random values:
+## Encoding text[[encoding-text]]
+
+Transformer models handle text by turning the inputs into numbers. Here we will look at exactly what happens when your text is processed by the tokenizer. We've already seen in [Chapter 1](/course/chapter1) that tokenizers split the text into tokens and then convert these tokens into numbers. We can see this conversion through a simple tokenizer:
-{#if fw === 'pt'}
```py
-from transformers import BertConfig, BertModel
+from transformers import AutoTokenizer
-config = BertConfig()
-model = BertModel(config)
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-# Model is randomly initialized!
+encoded_input = tokenizer("Hello, I'm a single sentence!")
+print(encoded_input)
```
-{:else}
-```py
-from transformers import BertConfig, TFBertModel
-config = BertConfig()
-model = TFBertModel(config)
+```python out
+{'input_ids': [101, 8667, 117, 1000, 1045, 1005, 1049, 2235, 17662, 12172, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+We get a dictionary with the following fields:
+- input_ids: numerical representations of your tokens
+- token_type_ids: these tell the model which part of the input is sentence A and which is sentence B (discussed more in the next section)
+- attention_mask: this indicates which tokens should be attended to and which should not (discussed more in a bit)
+
+We can decode the input IDs to get back the original text:
+
+```py
+tokenizer.decode(encoded_input["input_ids"])
+```
-# Model is randomly initialized!
+```python out
+"[CLS] Hello, I'm a single sentence! [SEP]"
```
-{/if}
-The model can be used in this state, but it will output gibberish; it needs to be trained first. We could train the model from scratch on the task at hand, but as you saw in [Chapter 1](/course/chapter1), this would require a long time and a lot of data, and it would have a non-negligible environmental impact. To avoid unnecessary and duplicated effort, it's imperative to be able to share and reuse models that have already been trained.
+You'll notice that the tokenizer has added special tokens — `[CLS]` and `[SEP]` — required by the model. Not all models need special tokens; they're utilized when a model was pretrained with them, in which case the tokenizer needs to add them as that model expects these tokens.
-Loading a Transformer model that is already trained is simple — we can do this using the `from_pretrained()` method:
+You can encode multiple sentences at once, either by batching them together (we'll discuss this soon) or by passing a list:
-{#if fw === 'pt'}
```py
-from transformers import BertModel
+encoded_input = tokenizer("How are you?", "I'm fine, thank you!")
+print(encoded_input)
+```
-model = BertModel.from_pretrained("bert-base-cased")
+```python out
+{'input_ids': [[101, 1731, 1132, 1128, 136, 102], [101, 1045, 1005, 1049, 2503, 117, 5763, 1128, 136, 102]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
```
-As you saw earlier, we could replace `BertModel` with the equivalent `AutoModel` class. We'll do this from now on as this produces checkpoint-agnostic code; if your code works for one checkpoint, it should work seamlessly with another. This applies even if the architecture is different, as long as the checkpoint was trained for a similar task (for example, a sentiment analysis task).
+Note that when passing multiple sentences, the tokenizer returns a list for each sentence for each dictionary value. We can also ask the tokenizer to return tensors directly from PyTorch:
-{:else}
```py
-from transformers import TFBertModel
+encoded_input = tokenizer("How are you?", "I'm fine, thank you!", return_tensors="pt")
+print(encoded_input)
+```
-model = TFBertModel.from_pretrained("bert-base-cased")
+```python out
+{'input_ids': tensor([[ 101, 1731, 1132, 1128, 136, 102],
+ [ 101, 1045, 1005, 1049, 2503, 117, 5763, 1128, 136, 102]]),
+ 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
+ 'attention_mask': tensor([[1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
```
-As you saw earlier, we could replace `TFBertModel` with the equivalent `TFAutoModel` class. We'll do this from now on as this produces checkpoint-agnostic code; if your code works for one checkpoint, it should work seamlessly with another. This applies even if the architecture is different, as long as the checkpoint was trained for a similar task (for example, a sentiment analysis task).
+But there's a problem: the two lists don't have the same length! Arrays and tensors need to be rectangular, so we can't simply convert these lists to a PyTorch tensor (or NumPy array). The tokenizer provides an option for that: padding.
-{/if}
+### Padding inputs[[padding-inputs]]
-In the code sample above we didn't use `BertConfig`, and instead loaded a pretrained model via the `bert-base-cased` identifier. This is a model checkpoint that was trained by the authors of BERT themselves; you can find more details about it in its [model card](https://huggingface.co/bert-base-cased).
+If we ask the tokenizer to pad the inputs, it will make all sentences the same length by adding a special padding token to the sentences that are shorter than the longest one:
-This model is now initialized with all the weights of the checkpoint. It can be used directly for inference on the tasks it was trained on, and it can also be fine-tuned on a new task. By training with pretrained weights rather than from scratch, we can quickly achieve good results.
+```py
+encoded_input = tokenizer(
+ ["How are you?", "I'm fine, thank you!"], padding=True, return_tensors="pt"
+)
+print(encoded_input)
+```
-The weights have been downloaded and cached (so future calls to the `from_pretrained()` method won't re-download them) in the cache folder, which defaults to *~/.cache/huggingface/transformers*. You can customize your cache folder by setting the `HF_HOME` environment variable.
+```python out
+{'input_ids': tensor([[ 101, 1731, 1132, 1128, 136, 102, 0, 0, 0, 0],
+ [ 101, 1045, 1005, 1049, 2503, 117, 5763, 1128, 136, 102]]),
+ 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
+ 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
+```
-The identifier used to load the model can be the identifier of any model on the Model Hub, as long as it is compatible with the BERT architecture. The entire list of available BERT checkpoints can be found [here](https://huggingface.co/models?filter=bert).
+Now we have rectangular tensors! Note that the padding tokens have been encoded into input IDs with ID 0, and they have an attention mask value of 0 as well. This is because those padding tokens shouldn't be analyzed by the model: they're not part of the actual sentence.
-### Saving methods[[saving-methods]]
+### Truncating inputs[[truncating-inputs]]
-Saving a model is as easy as loading one — we use the `save_pretrained()` method, which is analogous to the `from_pretrained()` method:
+The tensors might get too big to be processed by the model. For instance, BERT was only pretrained with sequences up to 512 tokens, so it cannot process longer sequences. If you have sequences longer than the model can handle, you'll need to truncate them with the `truncation` parameter:
```py
-model.save_pretrained("directory_on_my_computer")
+encoded_input = tokenizer(
+ "This is a very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very very long sentence.",
+ truncation=True,
+)
+print(encoded_input["input_ids"])
```
-This saves two files to your disk:
-
-{#if fw === 'pt'}
+```python out
+[101, 1188, 1110, 170, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1505, 1179, 5650, 119, 102]
```
-ls directory_on_my_computer
-config.json pytorch_model.bin
-```
-{:else}
-```
-ls directory_on_my_computer
+By combining the padding and truncation arguments, you can make sure your tensors have the exact size you need:
-config.json tf_model.h5
+```py
+encoded_input = tokenizer(
+ ["How are you?", "I'm fine, thank you!"],
+ padding=True,
+ truncation=True,
+ max_length=5,
+ return_tensors="pt",
+)
+print(encoded_input)
```
-{/if}
-If you take a look at the *config.json* file, you'll recognize the attributes necessary to build the model architecture. This file also contains some metadata, such as where the checkpoint originated and what 🤗 Transformers version you were using when you last saved the checkpoint.
+```python out
+{'input_ids': tensor([[ 101, 1731, 1132, 1128, 102],
+ [ 101, 1045, 1005, 1049, 102]]),
+ 'token_type_ids': tensor([[0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0]]),
+ 'attention_mask': tensor([[1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1]])}
+```
-{#if fw === 'pt'}
-The *pytorch_model.bin* file is known as the *state dictionary*; it contains all your model's weights. The two files go hand in hand; the configuration is necessary to know your model's architecture, while the model weights are your model's parameters.
+### Adding special tokens
-{:else}
-The *tf_model.h5* file is known as the *state dictionary*; it contains all your model's weights. The two files go hand in hand; the configuration is necessary to know your model's architecture, while the model weights are your model's parameters.
+Special tokens (or at least the concept of them) is particularly important to BERT and derived models. These tokens are added to better represent the sentence boundaries, such as the beginning of a sentence (`[CLS]`) or separator between sentences (`[SEP]`). Let's look at a simple example:
-{/if}
+```py
+encoded_input = tokenizer("How are you?")
+print(encoded_input["input_ids"])
+tokenizer.decode(encoded_input["input_ids"])
+```
-## Using a Transformer model for inference[[using-a-transformer-model-for-inference]]
+```python out
+[101, 1731, 1132, 1128, 136, 102]
+'[CLS] How are you? [SEP]'
+```
-Now that you know how to load and save a model, let's try using it to make some predictions. Transformer models can only process numbers — numbers that the tokenizer generates. But before we discuss tokenizers, let's explore what inputs the model accepts.
+These special tokens are automatically added by the tokenizer. Not all models need special tokens; they are primarily used when a model was pretrained with them, in which case the tokenizer will add them since the model expects them.
-Tokenizers can take care of casting the inputs to the appropriate framework's tensors, but to help you understand what's going on, we'll take a quick look at what must be done before sending the inputs to the model.
+### Why is all of this necessary?
-Let's say we have a couple of sequences:
+Here's a concrete example. Consider these encoded sequences:
```py
-sequences = ["Hello!", "Cool.", "Nice!"]
+sequences = [
+ "I've been waiting for a HuggingFace course my whole life.",
+ "I hate this so much!",
+]
```
-The tokenizer converts these to vocabulary indices which are typically called *input IDs*. Each sequence is now a list of numbers! The resulting output is:
+Once tokenized, we have:
-```py no-format
+```python
encoded_sequences = [
- [101, 7592, 999, 102],
- [101, 4658, 1012, 102],
- [101, 3835, 999, 102],
+ [
+ 101,
+ 1045,
+ 1005,
+ 2310,
+ 2042,
+ 3403,
+ 2005,
+ 1037,
+ 17662,
+ 12172,
+ 2607,
+ 2026,
+ 2878,
+ 2166,
+ 1012,
+ 102,
+ ],
+ [101, 1045, 5223, 2023, 2061, 2172, 999, 102],
]
```
This is a list of encoded sequences: a list of lists. Tensors only accept rectangular shapes (think matrices). This "array" is already of rectangular shape, so converting it to a tensor is easy:
-{#if fw === 'pt'}
```py
import torch
model_inputs = torch.tensor(encoded_sequences)
```
-{:else}
-```py
-import tensorflow as tf
-
-model_inputs = tf.constant(encoded_sequences)
-```
-{/if}
### Using the tensors as inputs to the model[[using-the-tensors-as-inputs-to-the-model]]
diff --git a/chapters/en/chapter2/4.mdx b/chapters/en/chapter2/4.mdx
index 30167ddbd..d07264690 100644
--- a/chapters/en/chapter2/4.mdx
+++ b/chapters/en/chapter2/4.mdx
@@ -2,8 +2,6 @@
# Tokenizers[[tokenizers]]
-{#if fw === 'pt'}
-
-{:else}
-
-
-
-{/if}
-
Tokenizers are one of the core components of the NLP pipeline. They serve one purpose: to translate text into data that can be processed by the model. Models can only process numbers, so tokenizers need to convert our text inputs to numerical data. In this section, we'll explore exactly what happens in the tokenization pipeline.
@@ -131,14 +118,8 @@ from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
```
-{#if fw === 'pt'}
Similar to `AutoModel`, the `AutoTokenizer` class will grab the proper tokenizer class in the library based on the checkpoint name, and can be used directly with any checkpoint:
-{:else}
-Similar to `TFAutoModel`, the `AutoTokenizer` class will grab the proper tokenizer class in the library based on the checkpoint name, and can be used directly with any checkpoint:
-
-{/if}
-
```py
from transformers import AutoTokenizer
diff --git a/chapters/en/chapter2/5.mdx b/chapters/en/chapter2/5.mdx
index 33060505b..299a15c5f 100644
--- a/chapters/en/chapter2/5.mdx
+++ b/chapters/en/chapter2/5.mdx
@@ -2,8 +2,6 @@
# Handling multiple sequences[[handling-multiple-sequences]]
-{#if fw === 'pt'}
-
-{:else}
-
-
-
-{/if}
-
-{#if fw === 'pt'}
-{:else}
-
-{/if}
In the previous section, we explored the simplest of use cases: doing inference on a single sequence of a small length. However, some questions emerge already:
@@ -41,7 +24,6 @@ Let's see what kinds of problems these questions pose, and how we can solve them
In the previous exercise you saw how sequences get translated into lists of numbers. Let's convert this list of numbers to a tensor and send it to the model:
-{#if fw === 'pt'}
```py
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
@@ -62,34 +44,11 @@ model(input_ids)
```python out
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
```
-{:else}
-```py
-import tensorflow as tf
-from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
-
-sequence = "I've been waiting for a HuggingFace course my whole life."
-
-tokens = tokenizer.tokenize(sequence)
-ids = tokenizer.convert_tokens_to_ids(tokens)
-input_ids = tf.constant(ids)
-# This line will fail.
-model(input_ids)
-```
-
-```py out
-InvalidArgumentError: Input to reshape is a tensor with 14 values, but the requested shape has 196 [Op:Reshape]
-```
-{/if}
Oh no! Why did this fail? We followed the steps from the pipeline in section 2.
The problem is that we sent a single sequence to the model, whereas 🤗 Transformers models expect multiple sentences by default. Here we tried to do everything the tokenizer did behind the scenes when we applied it to a `sequence`. But if you look closely, you'll see that the tokenizer didn't just convert the list of input IDs into a tensor, it added a dimension on top of it:
-{#if fw === 'pt'}
```py
tokenized_inputs = tokenizer(sequence, return_tensors="pt")
print(tokenized_inputs["input_ids"])
@@ -99,22 +58,9 @@ print(tokenized_inputs["input_ids"])
tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,
2607, 2026, 2878, 2166, 1012, 102]])
```
-{:else}
-```py
-tokenized_inputs = tokenizer(sequence, return_tensors="tf")
-print(tokenized_inputs["input_ids"])
-```
-
-```py out
-
-```
-{/if}
Let's try again and add a new dimension:
-{#if fw === 'pt'}
```py
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
@@ -134,43 +80,13 @@ print("Input IDs:", input_ids)
output = model(input_ids)
print("Logits:", output.logits)
```
-{:else}
-```py
-import tensorflow as tf
-from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
-
-sequence = "I've been waiting for a HuggingFace course my whole life."
-
-tokens = tokenizer.tokenize(sequence)
-ids = tokenizer.convert_tokens_to_ids(tokens)
-
-input_ids = tf.constant([ids])
-print("Input IDs:", input_ids)
-
-output = model(input_ids)
-print("Logits:", output.logits)
-```
-{/if}
We print the input IDs as well as the resulting logits — here's the output:
-{#if fw === 'pt'}
```python out
Input IDs: [[ 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]]
Logits: [[-2.7276, 2.8789]]
```
-{:else}
-```py out
-Input IDs: tf.Tensor(
-[[ 1045 1005 2310 2042 3403 2005 1037 17662 12172 2607 2026 2878
- 2166 1012]], shape=(1, 14), dtype=int32)
-Logits: tf.Tensor([[-2.7276208 2.8789377]], shape=(1, 2), dtype=float32)
-```
-{/if}
*Batching* is the act of sending multiple sentences through the model, all at once. If you only have one sentence, you can just build a batch with a single sequence:
@@ -212,7 +128,6 @@ batched_ids = [
The padding token ID can be found in `tokenizer.pad_token_id`. Let's use it and send our two sentences through the model individually and batched together:
-{#if fw === 'pt'}
```py no-format
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
@@ -234,30 +149,6 @@ tensor([[ 0.5803, -0.4125]], grad_fn=)
tensor([[ 1.5694, -1.3895],
[ 1.3373, -1.2163]], grad_fn=)
```
-{:else}
-```py no-format
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
-
-sequence1_ids = [[200, 200, 200]]
-sequence2_ids = [[200, 200]]
-batched_ids = [
- [200, 200, 200],
- [200, 200, tokenizer.pad_token_id],
-]
-
-print(model(tf.constant(sequence1_ids)).logits)
-print(model(tf.constant(sequence2_ids)).logits)
-print(model(tf.constant(batched_ids)).logits)
-```
-
-```py out
-tf.Tensor([[ 1.5693678 -1.3894581]], shape=(1, 2), dtype=float32)
-tf.Tensor([[ 0.5803005 -0.41252428]], shape=(1, 2), dtype=float32)
-tf.Tensor(
-[[ 1.5693681 -1.3894582]
- [ 1.3373486 -1.2163193]], shape=(2, 2), dtype=float32)
-```
-{/if}
There's something wrong with the logits in our batched predictions: the second row should be the same as the logits for the second sentence, but we've got completely different values!
@@ -269,7 +160,6 @@ This is because the key feature of Transformer models is attention layers that *
Let's complete the previous example with an attention mask:
-{#if fw === 'pt'}
```py no-format
batched_ids = [
[200, 200, 200],
@@ -289,28 +179,6 @@ print(outputs.logits)
tensor([[ 1.5694, -1.3895],
[ 0.5803, -0.4125]], grad_fn=)
```
-{:else}
-```py no-format
-batched_ids = [
- [200, 200, 200],
- [200, 200, tokenizer.pad_token_id],
-]
-
-attention_mask = [
- [1, 1, 1],
- [1, 1, 0],
-]
-
-outputs = model(tf.constant(batched_ids), attention_mask=tf.constant(attention_mask))
-print(outputs.logits)
-```
-
-```py out
-tf.Tensor(
-[[ 1.5693681 -1.3894582 ]
- [ 0.5803021 -0.41252586]], shape=(2, 2), dtype=float32)
-```
-{/if}
Now we get the same logits for the second sentence in the batch.
diff --git a/chapters/en/chapter2/6.mdx b/chapters/en/chapter2/6.mdx
index d26118501..3a0dac876 100644
--- a/chapters/en/chapter2/6.mdx
+++ b/chapters/en/chapter2/6.mdx
@@ -2,8 +2,6 @@
# Putting it all together[[putting-it-all-together]]
-{#if fw === 'pt'}
-
-{:else}
-
-
-
-{/if}
-
In the last few sections, we've been trying our best to do most of the work by hand. We've explored how tokenizers work and looked at tokenization, conversion to input IDs, padding, truncation, and attention masks.
However, as we saw in section 2, the 🤗 Transformers API can handle all of this for us with a high-level function that we'll dive into here. When you call your `tokenizer` directly on the sentence, you get back inputs that are ready to pass through your model:
@@ -82,7 +69,7 @@ model_inputs = tokenizer(sequences, truncation=True)
model_inputs = tokenizer(sequences, max_length=8, truncation=True)
```
-The `tokenizer` object can handle the conversion to specific framework tensors, which can then be directly sent to the model. For example, in the following code sample we are prompting the tokenizer to return tensors from the different frameworks — `"pt"` returns PyTorch tensors, `"tf"` returns TensorFlow tensors, and `"np"` returns NumPy arrays:
+The `tokenizer` object can handle the conversion to specific framework tensors, which can then be directly sent to the model. For example, in the following code sample we are prompting the tokenizer to return tensors from the different frameworks — `"pt"` returns PyTorch tensors and `"np"` returns NumPy arrays:
```py
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
@@ -90,9 +77,6 @@ sequences = ["I've been waiting for a HuggingFace course my whole life.", "So ha
# Returns PyTorch tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
-# Returns TensorFlow tensors
-model_inputs = tokenizer(sequences, padding=True, return_tensors="tf")
-
# Returns NumPy arrays
model_inputs = tokenizer(sequences, padding=True, return_tensors="np")
```
@@ -135,7 +119,6 @@ The tokenizer added the special word `[CLS]` at the beginning and the special wo
Now that we've seen all the individual steps the `tokenizer` object uses when applied on texts, let's see one final time how it can handle multiple sequences (padding!), very long sequences (truncation!), and multiple types of tensors with its main API:
-{#if fw === 'pt'}
```py
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
@@ -148,17 +131,3 @@ sequences = ["I've been waiting for a HuggingFace course my whole life.", "So ha
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)
```
-{:else}
-```py
-import tensorflow as tf
-from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
-
-checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
-tokenizer = AutoTokenizer.from_pretrained(checkpoint)
-model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
-sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
-
-tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="tf")
-output = model(**tokens)
-```
-{/if}
diff --git a/chapters/en/chapter2/8.mdx b/chapters/en/chapter2/8.mdx
index c41f27936..f2f7ab431 100644
--- a/chapters/en/chapter2/8.mdx
+++ b/chapters/en/chapter2/8.mdx
@@ -1,310 +1,821 @@
-
-
-
-
-# End-of-chapter quiz[[end-of-chapter-quiz]]
-
-
-
-### 1. What is the order of the language modeling pipeline?
-
-
-
-### 2. How many dimensions does the tensor output by the base Transformer model have, and what are they?
-
-
-
-### 3. Which of the following is an example of subword tokenization?
-
-
-
-### 4. What is a model head?
-
-
-
-{#if fw === 'pt'}
-### 5. What is an AutoModel?
-
-AutoTrain product?"
- },
- {
- text: "An object that returns the correct architecture based on the checkpoint",
- explain: "Exactly: the AutoModel only needs to know the checkpoint from which to initialize to return the correct architecture.",
- correct: true
- },
- {
- text: "A model that automatically detects the language used for its inputs to load the correct weights",
- explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the Model Hub to find the best checkpoint for your task!"
- }
- ]}
-/>
-
-{:else}
-### 5. What is an TFAutoModel?
-
-AutoTrain product?"
- },
- {
- text: "An object that returns the correct architecture based on the checkpoint",
- explain: "Exactly: the TFAutoModel only needs to know the checkpoint from which to initialize to return the correct architecture.",
- correct: true
- },
- {
- text: "A model that automatically detects the language used for its inputs to load the correct weights",
- explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the Model Hub to find the best checkpoint for your task!"
- }
- ]}
-/>
-
-{/if}
-
-### 6. What are the techniques to be aware of when batching sequences of different lengths together?
-
-
-
-### 7. What is the point of applying a SoftMax function to the logits output by a sequence classification model?
-
-
-
-### 8. What method is most of the tokenizer API centered around?
-
-encode, as it can encode text into IDs and IDs into predictions",
- explain: "Wrong! While the encode method does exist on tokenizers, it does not exist on models."
- },
- {
- text: "Calling the tokenizer object directly.",
- explain: "Exactly! The __call__ method of the tokenizer is a very powerful method which can handle pretty much anything. It is also the method used to retrieve predictions from a model.",
- correct: true
- },
- {
- text: "pad",
- explain: "Wrong! Padding is very useful, but it's just one part of the tokenizer API."
- },
- {
- text: "tokenize",
- explain: "The tokenize method is arguably one of the most useful methods, but it isn't the core of the tokenizer API."
- }
- ]}
-/>
-
-### 9. What does the `result` variable contain in this code sample?
-
-```py
-from transformers import AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-result = tokenizer.tokenize("Hello!")
-```
-
-__call__ or convert_tokens_to_ids method is for!"
- },
- {
- text: "A string containing all of the tokens",
- explain: "This would be suboptimal, as the goal is to split the string into multiple tokens."
- }
- ]}
-/>
-
-{#if fw === 'pt'}
-### 10. Is there something wrong with the following code?
-
-```py
-from transformers import AutoTokenizer, AutoModel
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-model = AutoModel.from_pretrained("gpt2")
-
-encoded = tokenizer("Hey!", return_tensors="pt")
-result = model(**encoded)
-```
-
-
-
-{:else}
-### 10. Is there something wrong with the following code?
-
-```py
-from transformers import AutoTokenizer, TFAutoModel
-
-tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
-model = TFAutoModel.from_pretrained("gpt2")
-
-encoded = tokenizer("Hey!", return_tensors="pt")
-result = model(**encoded)
-```
-
-
-
-{/if}
+# Optimized Inference Deployment
+
+In this section, we'll explore advanced frameworks for optimizing LLM deployments: Text Generation Inference (TGI), vLLM, and llama.cpp. These applications are primarily used in production environments to serve LLMs to users. This section focuses on how to deploy these frameworks in production rather than how to use them for inference on a single machine.
+
+We'll cover how these tools maximize inference efficiency and simplify production deployments of Large Language Models.
+
+## Framework Selection Guide
+
+TGI, vLLM, and llama.cpp serve similar purposes but have distinct characteristics that make them better suited for different use cases. Let's look at the key differences between them, focusing on performance and integration.
+
+### Memory Management and Performance
+
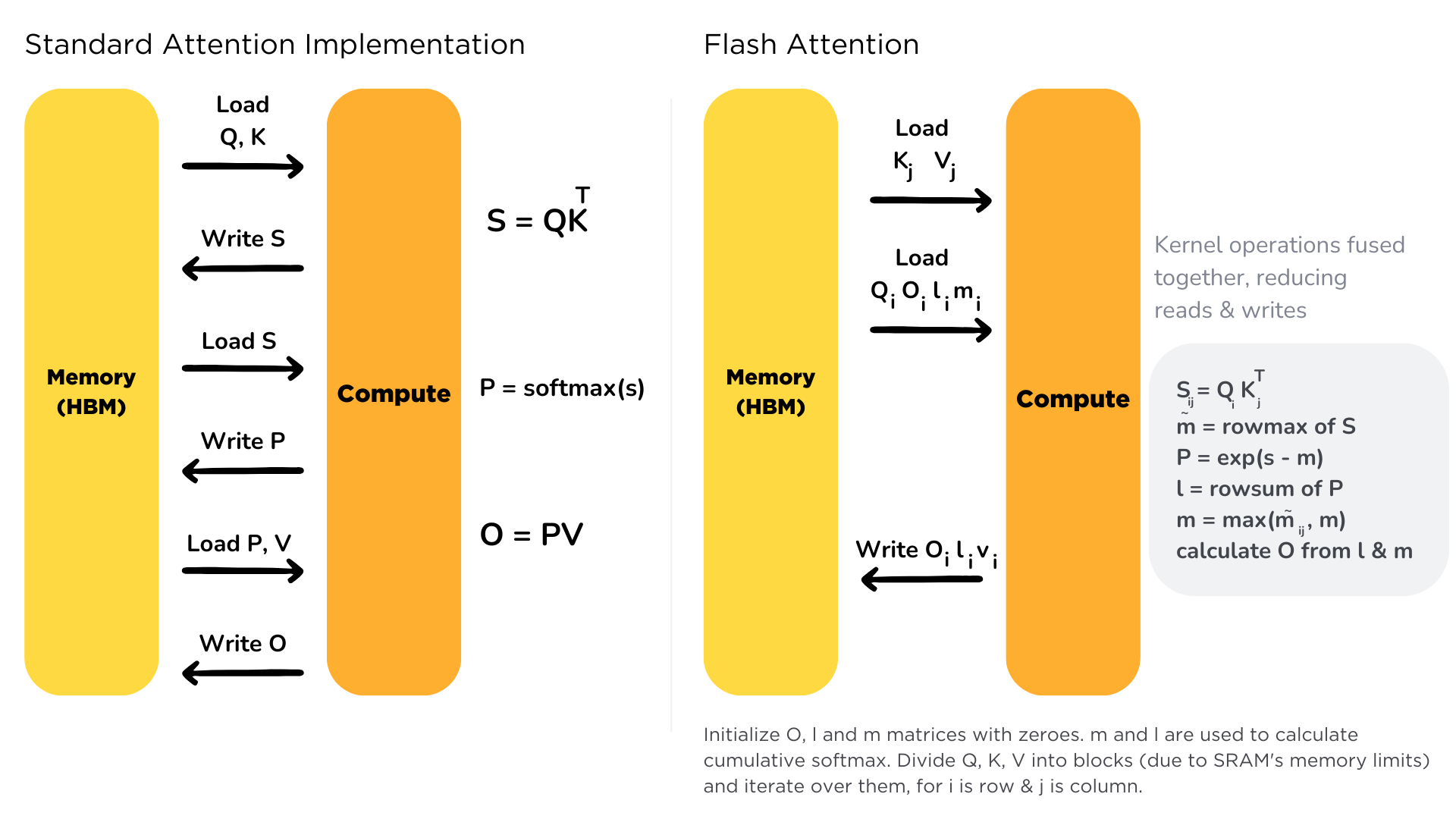
+**TGI** is designed to be stable and predictable in production, using fixed sequence lengths to keep memory usage consistent. TGI manages memory using Flash Attention 2 and continuous batching techniques. This means it can process attention calculations very efficiently and keep the GPU busy by constantly feeding it work. The system can move parts of the model between CPU and GPU when needed, which helps handle larger models.
+
+ +
+
+Flash Attention is a technique that optimizes the attention mechanism in transformer models by addressing memory bandwidth bottlenecks. As discussed earlier in [Chapter 1.8](/course/chapter1/8), the attention mechanism has quadratic complexity and memory usage, making it inefficient for long sequences.
+
+The key innovation is in how it manages memory transfers between High Bandwidth Memory (HBM) and faster SRAM cache. Traditional attention repeatedly transfers data between HBM and SRAM, creating bottlenecks by leaving the GPU idle. Flash Attention loads data once into SRAM and performs all calculations there, minimizing expensive memory transfers.
+
+While the benefits are most significant during training, Flash Attention's reduced VRAM usage and improved efficiency make it valuable for inference as well, enabling faster and more scalable LLM serving.
+
+
+**vLLM** takes a different approach by using PagedAttention. Just like how a computer manages its memory in pages, vLLM splits the model's memory into smaller blocks. This clever system means it can handle different-sized requests more flexibly and doesn't waste memory space. It's particularly good at sharing memory between different requests and reduces memory fragmentation, which makes the whole system more efficient.
+
+
+PagedAttention is a technique that addresses another critical bottleneck in LLM inference: KV cache memory management. As discussed in [Chapter 1.8](/course/chapter1/8), during text generation, the model stores attention keys and values (KV cache) for each generated token to reduce redundant computations. The KV cache can become enormous, especially with long sequences or multiple concurrent requests.
+
+vLLM's key innovation lies in how it manages this cache:
+
+1. **Memory Paging**: Instead of treating the KV cache as one large block, it's divided into fixed-size "pages" (similar to virtual memory in operating systems).
+2. **Non-contiguous Storage**: Pages don't need to be stored contiguously in GPU memory, allowing for more flexible memory allocation.
+3. **Page Table Management**: A page table tracks which pages belong to which sequence, enabling efficient lookup and access.
+4. **Memory Sharing**: For operations like parallel sampling, pages storing the KV cache for the prompt can be shared across multiple sequences.
+
+The PagedAttention approach can lead to up to 24x higher throughput compared to traditional methods, making it a game-changer for production LLM deployments. If you want to go really deep into how PagedAttention works, you can read the [the guide from the vLLM documentation](https://docs.vllm.ai/en/latest/design/kernel/paged_attention.html).
+
+
+**llama.cpp** is a highly optimized C/C++ implementation originally designed for running LLaMA models on consumer hardware. It focuses on CPU efficiency with optional GPU acceleration and is ideal for resource-constrained environments. llama.cpp uses quantization techniques to reduce model size and memory requirements while maintaining good performance. It implements optimized kernels for various CPU architectures and supports basic KV cache management for efficient token generation.
+
+
+Quantization in llama.cpp reduces the precision of model weights from 32-bit or 16-bit floating point to lower precision formats like 8-bit integers (INT8), 4-bit, or even lower. This significantly reduces memory usage and improves inference speed with minimal quality loss.
+
+Key quantization features in llama.cpp include:
+1. **Multiple Quantization Levels**: Supports 8-bit, 4-bit, 3-bit, and even 2-bit quantization
+2. **GGML/GGUF Format**: Uses custom tensor formats optimized for quantized inference
+3. **Mixed Precision**: Can apply different quantization levels to different parts of the model
+4. **Hardware-Specific Optimizations**: Includes optimized code paths for various CPU architectures (AVX2, AVX-512, NEON)
+
+This approach enables running billion-parameter models on consumer hardware with limited memory, making it perfect for local deployments and edge devices.
+
+
+
+
+### Deployment and Integration
+
+Let's move on to the deployment and integration differences between the frameworks.
+
+**TGI** excels in enterprise-level deployment with its production-ready features. It comes with built-in Kubernetes support and includes everything you need for running in production, like monitoring through Prometheus and Grafana, automatic scaling, and comprehensive safety features. The system also includes enterprise-grade logging and various protective measures like content filtering and rate limiting to keep your deployment secure and stable.
+
+**vLLM** takes a more flexible, developer-friendly approach to deployment. It's built with Python at its core and can easily replace OpenAI's API in your existing applications. The framework focuses on delivering raw performance and can be customized to fit your specific needs. It works particularly well with Ray for managing clusters, making it a great choice when you need high performance and adaptability.
+
+**llama.cpp** prioritizes simplicity and portability. Its server implementation is lightweight and can run on a wide range of hardware, from powerful servers to consumer laptops and even some high-end mobile devices. With minimal dependencies and a simple C/C++ core, it's easy to deploy in environments where installing Python frameworks would be challenging. The server provides an OpenAI-compatible API while maintaining a much smaller resource footprint than other solutions.
+
+
+
+## Getting Started
+
+Let's explore how to use these frameworks for deploying LLMs, starting with installation and basic setup.
+
+### Installation and Basic Setup
+
+
+
+
+
+TGI is easy to install and use, with deep integration into the Hugging Face ecosystem.
+
+First, launch the TGI server using Docker:
+
+```sh
+docker run --gpus all \
+ --shm-size 1g \
+ -p 8080:80 \
+ -v ~/.cache/huggingface:/data \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-360M-Instruct
+```
+
+Then interact with it using Hugging Face's InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to TGI endpoint
+client = InferenceClient(
+ model="http://localhost:8080", # URL to the TGI server
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+ stop_sequences=[],
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+Alternatively, you can use the OpenAI client:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to TGI endpoint
+client = OpenAI(
+ base_url="http://localhost:8080/v1", # Make sure to include /v1
+ api_key="not-needed", # TGI doesn't require an API key by default
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+llama.cpp is easy to install and use, requiring minimal dependencies and supporting both CPU and GPU inference.
+
+First, install and build llama.cpp:
+
+```sh
+# Clone the repository
+git clone https://github.com/ggerganov/llama.cpp
+cd llama.cpp
+
+# Build the project
+make
+
+# Download the SmolLM2-1.7B-Instruct-GGUF model
+curl -L -O https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct-GGUF/resolve/main/smollm2-1.7b-instruct.Q4_K_M.gguf
+```
+
+Then, launch the server (with OpenAI API compatibility):
+
+```sh
+# Start the server
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 4096 \
+ --n-gpu-layers 0 # Set to a higher number to use GPU
+```
+
+Interact with the server using Hugging Face's InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to llama.cpp server
+client = InferenceClient(
+ model="http://localhost:8080/v1", # URL to the llama.cpp server
+ token="sk-no-key-required", # llama.cpp server requires this placeholder
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+Alternatively, you can use the OpenAI client:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to llama.cpp server
+client = OpenAI(
+ base_url="http://localhost:8080/v1",
+ api_key="sk-no-key-required", # llama.cpp server requires this placeholder
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="smollm2-1.7b-instruct", # Model identifier can be anything as server only loads one model
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+vLLM is easy to install and use, with both OpenAI API compatibility and a native Python interface.
+
+First, launch the vLLM OpenAI-compatible server:
+
+```sh
+python -m vllm.entrypoints.openai.api_server \
+ --model HuggingFaceTB/SmolLM2-360M-Instruct \
+ --host 0.0.0.0 \
+ --port 8000
+```
+
+Then interact with it using Hugging Face's InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to vLLM endpoint
+client = InferenceClient(
+ model="http://localhost:8000/v1", # URL to the vLLM server
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+Alternatively, you can use the OpenAI client:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to vLLM endpoint
+client = OpenAI(
+ base_url="http://localhost:8000/v1",
+ api_key="not-needed", # vLLM doesn't require an API key by default
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+### Basic Text Generation
+
+Let's look at examples of text generation with the frameworks:
+
+
+
+
+
+First, deploy TGI with advanced parameters:
+```sh
+docker run --gpus all \
+ --shm-size 1g \
+ -p 8080:80 \
+ -v ~/.cache/huggingface:/data \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-360M-Instruct \
+ --max-total-tokens 4096 \
+ --max-input-length 3072 \
+ --max-batch-total-tokens 8192 \
+ --waiting-served-ratio 1.2
+```
+
+Use the InferenceClient for flexible text generation:
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8080")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# Raw text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ repetition_penalty=1.1,
+ do_sample=True,
+ details=True,
+)
+print(response.generated_text)
+```
+
+Or use the OpenAI client:
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8080/v1", api_key="not-needed")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8, # Higher for more creativity
+)
+print(response.choices[0].message.content)
+```
+
+
+
+For llama.cpp, you can set advanced parameters when launching the server:
+
+```sh
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 4096 \ # Context size
+ --threads 8 \ # CPU threads to use
+ --batch-size 512 \ # Batch size for prompt evaluation
+ --n-gpu-layers 0 # GPU layers (0 = CPU only)
+```
+
+Use the InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8080/v1", token="sk-no-key-required")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# For direct text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ repetition_penalty=1.1,
+ details=True,
+)
+print(response.generated_text)
+```
+
+Or use the OpenAI client for generation with control over the sampling parameters:
+
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8080/v1", api_key="sk-no-key-required")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="smollm2-1.7b-instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Nucleus sampling probability
+ frequency_penalty=0.5, # Reduce repetition of frequent tokens
+ presence_penalty=0.5, # Reduce repetition by penalizing tokens already present
+ max_tokens=200, # Maximum generation length
+)
+print(response.choices[0].message.content)
+```
+
+You can also use llama.cpp's native library for even more control:
+
+```python
+# Using llama-cpp-python package for direct model access
+from llama_cpp import Llama
+
+# Load the model
+llm = Llama(
+ model_path="smollm2-1.7b-instruct.Q4_K_M.gguf",
+ n_ctx=4096, # Context window size
+ n_threads=8, # CPU threads
+ n_gpu_layers=0, # GPU layers (0 = CPU only)
+)
+
+# Format prompt according to the model's expected format
+prompt = """<|im_start|>system
+You are a creative storyteller.
+<|im_end|>
+<|im_start|>user
+Write a creative story
+<|im_end|>
+<|im_start|>assistant
+"""
+
+# Generate response with precise parameter control
+output = llm(
+ prompt,
+ max_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ frequency_penalty=0.5,
+ presence_penalty=0.5,
+ stop=["<|im_end|>"],
+)
+
+print(output["choices"][0]["text"])
+```
+
+
+
+For advanced usage with vLLM, you can use the InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8000/v1")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# For direct text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+```
+
+You can also use the OpenAI client:
+
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ top_p=0.95,
+ max_tokens=200,
+)
+print(response.choices[0].message.content)
+```
+
+vLLM also provides a native Python interface with fine-grained control:
+
+```python
+from vllm import LLM, SamplingParams
+
+# Initialize the model with advanced parameters
+llm = LLM(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ gpu_memory_utilization=0.85,
+ max_num_batched_tokens=8192,
+ max_num_seqs=256,
+ block_size=16,
+)
+
+# Configure sampling parameters
+sampling_params = SamplingParams(
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ max_tokens=100, # Maximum length
+ presence_penalty=1.1, # Reduce repetition
+ frequency_penalty=1.1, # Reduce repetition
+ stop=["\n\n", "###"], # Stop sequences
+)
+
+# Generate text
+prompt = "Write a creative story"
+outputs = llm.generate(prompt, sampling_params)
+print(outputs[0].outputs[0].text)
+
+# For chat-style interactions
+chat_prompt = [
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+]
+formatted_prompt = llm.get_chat_template()(chat_prompt) # Uses model's chat template
+outputs = llm.generate(formatted_prompt, sampling_params)
+print(outputs[0].outputs[0].text)
+```
+
+
+
+
+## Advanced Generation Control
+
+### Token Selection and Sampling
+
+The process of generating text involves selecting the next token at each step. This selection process can be controlled through various parameters:
+
+1. **Raw Logits**: The initial output probabilities for each token
+2. **Temperature**: Controls randomness in selection (higher = more creative)
+3. **Top-p (Nucleus) Sampling**: Filters to top tokens making up X% of probability mass
+4. **Top-k Filtering**: Limits selection to k most likely tokens
+
+Here's how to configure these parameters:
+
+
+
+
+
+```python
+client.generate(
+ "Write a creative story",
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ top_k=50, # Consider top 50 tokens
+ max_new_tokens=100, # Maximum length
+ repetition_penalty=1.1, # Reduce repetition
+)
+```
+
+
+
+```python
+# Via OpenAI API compatibility
+response = client.completions.create(
+ model="smollm2-1.7b-instruct", # Model name (can be any string for llama.cpp server)
+ prompt="Write a creative story",
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ frequency_penalty=1.1, # Reduce repetition
+ presence_penalty=0.1, # Reduce repetition
+ max_tokens=100, # Maximum length
+)
+
+# Via llama-cpp-python direct access
+output = llm(
+ "Write a creative story",
+ temperature=0.8,
+ top_p=0.95,
+ top_k=50,
+ max_tokens=100,
+ repeat_penalty=1.1,
+)
+```
+
+
+
+```python
+params = SamplingParams(
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ top_k=50, # Consider top 50 tokens
+ max_tokens=100, # Maximum length
+ presence_penalty=0.1, # Reduce repetition
+)
+llm.generate("Write a creative story", sampling_params=params)
+```
+
+
+
+
+### Controlling Repetition
+
+Both frameworks provide ways to prevent repetitive text generation:
+
+
+
+
+```python
+client.generate(
+ "Write a varied text",
+ repetition_penalty=1.1, # Penalize repeated tokens
+ no_repeat_ngram_size=3, # Prevent 3-gram repetition
+)
+```
+
+
+
+```python
+# Via OpenAI API
+response = client.completions.create(
+ model="smollm2-1.7b-instruct",
+ prompt="Write a varied text",
+ frequency_penalty=1.1, # Penalize frequent tokens
+ presence_penalty=0.8, # Penalize tokens already present
+)
+
+# Via direct library
+output = llm(
+ "Write a varied text",
+ repeat_penalty=1.1, # Penalize repeated tokens
+ frequency_penalty=0.5, # Additional frequency penalty
+ presence_penalty=0.5, # Additional presence penalty
+)
+```
+
+
+
+```python
+params = SamplingParams(
+ presence_penalty=0.1, # Penalize token presence
+ frequency_penalty=0.1, # Penalize token frequency
+)
+```
+
+
+
+
+### Length Control and Stop Sequences
+
+You can control generation length and specify when to stop:
+
+
+
+
+```python
+client.generate(
+ "Generate a short paragraph",
+ max_new_tokens=100,
+ min_new_tokens=10,
+ stop_sequences=["\n\n", "###"],
+)
+```
+
+
+
+```python
+# Via OpenAI API
+response = client.completions.create(
+ model="smollm2-1.7b-instruct",
+ prompt="Generate a short paragraph",
+ max_tokens=100,
+ stop=["\n\n", "###"],
+)
+
+# Via direct library
+output = llm("Generate a short paragraph", max_tokens=100, stop=["\n\n", "###"])
+```
+
+
+
+```python
+params = SamplingParams(
+ max_tokens=100,
+ min_tokens=10,
+ stop=["###", "\n\n"],
+ ignore_eos=False,
+ skip_special_tokens=True,
+)
+```
+
+
+
+
+## Memory Management
+
+Both frameworks implement advanced memory management techniques for efficient inference.
+
+
+
+
+TGI uses Flash Attention 2 and continuous batching:
+
+```sh
+# Docker deployment with memory optimization
+docker run --gpus all -p 8080:80 \
+ --shm-size 1g \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-1.7B-Instruct \
+ --max-batch-total-tokens 8192 \
+ --max-input-length 4096
+```
+
+
+
+llama.cpp uses quantization and optimized memory layout:
+
+```sh
+# Server with memory optimizations
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 2048 \ # Context size
+ --threads 4 \ # CPU threads
+ --n-gpu-layers 32 \ # Use more GPU layers for larger models
+ --mlock \ # Lock memory to prevent swapping
+ --cont-batching # Enable continuous batching
+```
+
+For models too large for your GPU, you can use CPU offloading:
+
+```sh
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --n-gpu-layers 20 \ # Keep first 20 layers on GPU
+ --threads 8 # Use more CPU threads for CPU layers
+```
+
+
+
+vLLM uses PagedAttention for optimal memory management:
+
+```python
+from vllm.engine.arg_utils import AsyncEngineArgs
+
+engine_args = AsyncEngineArgs(
+ model="HuggingFaceTB/SmolLM2-1.7B-Instruct",
+ gpu_memory_utilization=0.85,
+ max_num_batched_tokens=8192,
+ block_size=16,
+)
+
+llm = LLM(engine_args=engine_args)
+```
+
+
+
+
+## Resources
+
+- [Text Generation Inference Documentation](https://huggingface.co/docs/text-generation-inference)
+- [TGI GitHub Repository](https://github.com/huggingface/text-generation-inference)
+- [vLLM Documentation](https://vllm.readthedocs.io/)
+- [vLLM GitHub Repository](https://github.com/vllm-project/vllm)
+- [PagedAttention Paper](https://arxiv.org/abs/2309.06180)
+- [llama.cpp GitHub Repository](https://github.com/ggerganov/llama.cpp)
+- [llama-cpp-python Repository](https://github.com/abetlen/llama-cpp-python)
\ No newline at end of file
diff --git a/chapters/en/chapter2/9.mdx b/chapters/en/chapter2/9.mdx
new file mode 100644
index 000000000..1a375422a
--- /dev/null
+++ b/chapters/en/chapter2/9.mdx
@@ -0,0 +1,252 @@
+
+
+
+
+# End-of-chapter quiz[[end-of-chapter-quiz]]
+
+
+
+### 1. What is the order of the language modeling pipeline?
+
+
+
+### 2. How many dimensions does the tensor output by the base Transformer model have, and what are they?
+
+
+
+### 3. Which of the following is an example of subword tokenization?
+
+
+
+### 4. What is a model head?
+
+
+
+### 5. What is an AutoModel?
+
+AutoTrain product?"
+ },
+ {
+ text: "An object that returns the correct architecture based on the checkpoint",
+ explain: "Exactly: the
+
+
+Flash Attention is a technique that optimizes the attention mechanism in transformer models by addressing memory bandwidth bottlenecks. As discussed earlier in [Chapter 1.8](/course/chapter1/8), the attention mechanism has quadratic complexity and memory usage, making it inefficient for long sequences.
+
+The key innovation is in how it manages memory transfers between High Bandwidth Memory (HBM) and faster SRAM cache. Traditional attention repeatedly transfers data between HBM and SRAM, creating bottlenecks by leaving the GPU idle. Flash Attention loads data once into SRAM and performs all calculations there, minimizing expensive memory transfers.
+
+While the benefits are most significant during training, Flash Attention's reduced VRAM usage and improved efficiency make it valuable for inference as well, enabling faster and more scalable LLM serving.
+
+
+**vLLM** takes a different approach by using PagedAttention. Just like how a computer manages its memory in pages, vLLM splits the model's memory into smaller blocks. This clever system means it can handle different-sized requests more flexibly and doesn't waste memory space. It's particularly good at sharing memory between different requests and reduces memory fragmentation, which makes the whole system more efficient.
+
+
+PagedAttention is a technique that addresses another critical bottleneck in LLM inference: KV cache memory management. As discussed in [Chapter 1.8](/course/chapter1/8), during text generation, the model stores attention keys and values (KV cache) for each generated token to reduce redundant computations. The KV cache can become enormous, especially with long sequences or multiple concurrent requests.
+
+vLLM's key innovation lies in how it manages this cache:
+
+1. **Memory Paging**: Instead of treating the KV cache as one large block, it's divided into fixed-size "pages" (similar to virtual memory in operating systems).
+2. **Non-contiguous Storage**: Pages don't need to be stored contiguously in GPU memory, allowing for more flexible memory allocation.
+3. **Page Table Management**: A page table tracks which pages belong to which sequence, enabling efficient lookup and access.
+4. **Memory Sharing**: For operations like parallel sampling, pages storing the KV cache for the prompt can be shared across multiple sequences.
+
+The PagedAttention approach can lead to up to 24x higher throughput compared to traditional methods, making it a game-changer for production LLM deployments. If you want to go really deep into how PagedAttention works, you can read the [the guide from the vLLM documentation](https://docs.vllm.ai/en/latest/design/kernel/paged_attention.html).
+
+
+**llama.cpp** is a highly optimized C/C++ implementation originally designed for running LLaMA models on consumer hardware. It focuses on CPU efficiency with optional GPU acceleration and is ideal for resource-constrained environments. llama.cpp uses quantization techniques to reduce model size and memory requirements while maintaining good performance. It implements optimized kernels for various CPU architectures and supports basic KV cache management for efficient token generation.
+
+
+Quantization in llama.cpp reduces the precision of model weights from 32-bit or 16-bit floating point to lower precision formats like 8-bit integers (INT8), 4-bit, or even lower. This significantly reduces memory usage and improves inference speed with minimal quality loss.
+
+Key quantization features in llama.cpp include:
+1. **Multiple Quantization Levels**: Supports 8-bit, 4-bit, 3-bit, and even 2-bit quantization
+2. **GGML/GGUF Format**: Uses custom tensor formats optimized for quantized inference
+3. **Mixed Precision**: Can apply different quantization levels to different parts of the model
+4. **Hardware-Specific Optimizations**: Includes optimized code paths for various CPU architectures (AVX2, AVX-512, NEON)
+
+This approach enables running billion-parameter models on consumer hardware with limited memory, making it perfect for local deployments and edge devices.
+
+
+
+
+### Deployment and Integration
+
+Let's move on to the deployment and integration differences between the frameworks.
+
+**TGI** excels in enterprise-level deployment with its production-ready features. It comes with built-in Kubernetes support and includes everything you need for running in production, like monitoring through Prometheus and Grafana, automatic scaling, and comprehensive safety features. The system also includes enterprise-grade logging and various protective measures like content filtering and rate limiting to keep your deployment secure and stable.
+
+**vLLM** takes a more flexible, developer-friendly approach to deployment. It's built with Python at its core and can easily replace OpenAI's API in your existing applications. The framework focuses on delivering raw performance and can be customized to fit your specific needs. It works particularly well with Ray for managing clusters, making it a great choice when you need high performance and adaptability.
+
+**llama.cpp** prioritizes simplicity and portability. Its server implementation is lightweight and can run on a wide range of hardware, from powerful servers to consumer laptops and even some high-end mobile devices. With minimal dependencies and a simple C/C++ core, it's easy to deploy in environments where installing Python frameworks would be challenging. The server provides an OpenAI-compatible API while maintaining a much smaller resource footprint than other solutions.
+
+
+
+## Getting Started
+
+Let's explore how to use these frameworks for deploying LLMs, starting with installation and basic setup.
+
+### Installation and Basic Setup
+
+
+
+
+
+TGI is easy to install and use, with deep integration into the Hugging Face ecosystem.
+
+First, launch the TGI server using Docker:
+
+```sh
+docker run --gpus all \
+ --shm-size 1g \
+ -p 8080:80 \
+ -v ~/.cache/huggingface:/data \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-360M-Instruct
+```
+
+Then interact with it using Hugging Face's InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to TGI endpoint
+client = InferenceClient(
+ model="http://localhost:8080", # URL to the TGI server
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+ stop_sequences=[],
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+Alternatively, you can use the OpenAI client:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to TGI endpoint
+client = OpenAI(
+ base_url="http://localhost:8080/v1", # Make sure to include /v1
+ api_key="not-needed", # TGI doesn't require an API key by default
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+llama.cpp is easy to install and use, requiring minimal dependencies and supporting both CPU and GPU inference.
+
+First, install and build llama.cpp:
+
+```sh
+# Clone the repository
+git clone https://github.com/ggerganov/llama.cpp
+cd llama.cpp
+
+# Build the project
+make
+
+# Download the SmolLM2-1.7B-Instruct-GGUF model
+curl -L -O https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct-GGUF/resolve/main/smollm2-1.7b-instruct.Q4_K_M.gguf
+```
+
+Then, launch the server (with OpenAI API compatibility):
+
+```sh
+# Start the server
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 4096 \
+ --n-gpu-layers 0 # Set to a higher number to use GPU
+```
+
+Interact with the server using Hugging Face's InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to llama.cpp server
+client = InferenceClient(
+ model="http://localhost:8080/v1", # URL to the llama.cpp server
+ token="sk-no-key-required", # llama.cpp server requires this placeholder
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+Alternatively, you can use the OpenAI client:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to llama.cpp server
+client = OpenAI(
+ base_url="http://localhost:8080/v1",
+ api_key="sk-no-key-required", # llama.cpp server requires this placeholder
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="smollm2-1.7b-instruct", # Model identifier can be anything as server only loads one model
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+vLLM is easy to install and use, with both OpenAI API compatibility and a native Python interface.
+
+First, launch the vLLM OpenAI-compatible server:
+
+```sh
+python -m vllm.entrypoints.openai.api_server \
+ --model HuggingFaceTB/SmolLM2-360M-Instruct \
+ --host 0.0.0.0 \
+ --port 8000
+```
+
+Then interact with it using Hugging Face's InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+# Initialize client pointing to vLLM endpoint
+client = InferenceClient(
+ model="http://localhost:8000/v1", # URL to the vLLM server
+)
+
+# Text generation
+response = client.text_generation(
+ "Tell me a story",
+ max_new_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+
+# For chat format
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+Alternatively, you can use the OpenAI client:
+
+```python
+from openai import OpenAI
+
+# Initialize client pointing to vLLM endpoint
+client = OpenAI(
+ base_url="http://localhost:8000/v1",
+ api_key="not-needed", # vLLM doesn't require an API key by default
+)
+
+# Chat completion
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me a story"},
+ ],
+ max_tokens=100,
+ temperature=0.7,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+```
+
+
+
+
+### Basic Text Generation
+
+Let's look at examples of text generation with the frameworks:
+
+
+
+
+
+First, deploy TGI with advanced parameters:
+```sh
+docker run --gpus all \
+ --shm-size 1g \
+ -p 8080:80 \
+ -v ~/.cache/huggingface:/data \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-360M-Instruct \
+ --max-total-tokens 4096 \
+ --max-input-length 3072 \
+ --max-batch-total-tokens 8192 \
+ --waiting-served-ratio 1.2
+```
+
+Use the InferenceClient for flexible text generation:
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8080")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# Raw text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ repetition_penalty=1.1,
+ do_sample=True,
+ details=True,
+)
+print(response.generated_text)
+```
+
+Or use the OpenAI client:
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8080/v1", api_key="not-needed")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8, # Higher for more creativity
+)
+print(response.choices[0].message.content)
+```
+
+
+
+For llama.cpp, you can set advanced parameters when launching the server:
+
+```sh
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 4096 \ # Context size
+ --threads 8 \ # CPU threads to use
+ --batch-size 512 \ # Batch size for prompt evaluation
+ --n-gpu-layers 0 # GPU layers (0 = CPU only)
+```
+
+Use the InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8080/v1", token="sk-no-key-required")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# For direct text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ repetition_penalty=1.1,
+ details=True,
+)
+print(response.generated_text)
+```
+
+Or use the OpenAI client for generation with control over the sampling parameters:
+
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8080/v1", api_key="sk-no-key-required")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="smollm2-1.7b-instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Nucleus sampling probability
+ frequency_penalty=0.5, # Reduce repetition of frequent tokens
+ presence_penalty=0.5, # Reduce repetition by penalizing tokens already present
+ max_tokens=200, # Maximum generation length
+)
+print(response.choices[0].message.content)
+```
+
+You can also use llama.cpp's native library for even more control:
+
+```python
+# Using llama-cpp-python package for direct model access
+from llama_cpp import Llama
+
+# Load the model
+llm = Llama(
+ model_path="smollm2-1.7b-instruct.Q4_K_M.gguf",
+ n_ctx=4096, # Context window size
+ n_threads=8, # CPU threads
+ n_gpu_layers=0, # GPU layers (0 = CPU only)
+)
+
+# Format prompt according to the model's expected format
+prompt = """<|im_start|>system
+You are a creative storyteller.
+<|im_end|>
+<|im_start|>user
+Write a creative story
+<|im_end|>
+<|im_start|>assistant
+"""
+
+# Generate response with precise parameter control
+output = llm(
+ prompt,
+ max_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ frequency_penalty=0.5,
+ presence_penalty=0.5,
+ stop=["<|im_end|>"],
+)
+
+print(output["choices"][0]["text"])
+```
+
+
+
+For advanced usage with vLLM, you can use the InferenceClient:
+
+```python
+from huggingface_hub import InferenceClient
+
+client = InferenceClient(model="http://localhost:8000/v1")
+
+# Advanced parameters example
+response = client.chat_completion(
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ max_tokens=200,
+ top_p=0.95,
+)
+print(response.choices[0].message.content)
+
+# For direct text generation
+response = client.text_generation(
+ "Write a creative story about space exploration",
+ max_new_tokens=200,
+ temperature=0.8,
+ top_p=0.95,
+ details=True,
+)
+print(response.generated_text)
+```
+
+You can also use the OpenAI client:
+
+```python
+from openai import OpenAI
+
+client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
+
+# Advanced parameters example
+response = client.chat.completions.create(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ messages=[
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+ ],
+ temperature=0.8,
+ top_p=0.95,
+ max_tokens=200,
+)
+print(response.choices[0].message.content)
+```
+
+vLLM also provides a native Python interface with fine-grained control:
+
+```python
+from vllm import LLM, SamplingParams
+
+# Initialize the model with advanced parameters
+llm = LLM(
+ model="HuggingFaceTB/SmolLM2-360M-Instruct",
+ gpu_memory_utilization=0.85,
+ max_num_batched_tokens=8192,
+ max_num_seqs=256,
+ block_size=16,
+)
+
+# Configure sampling parameters
+sampling_params = SamplingParams(
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ max_tokens=100, # Maximum length
+ presence_penalty=1.1, # Reduce repetition
+ frequency_penalty=1.1, # Reduce repetition
+ stop=["\n\n", "###"], # Stop sequences
+)
+
+# Generate text
+prompt = "Write a creative story"
+outputs = llm.generate(prompt, sampling_params)
+print(outputs[0].outputs[0].text)
+
+# For chat-style interactions
+chat_prompt = [
+ {"role": "system", "content": "You are a creative storyteller."},
+ {"role": "user", "content": "Write a creative story"},
+]
+formatted_prompt = llm.get_chat_template()(chat_prompt) # Uses model's chat template
+outputs = llm.generate(formatted_prompt, sampling_params)
+print(outputs[0].outputs[0].text)
+```
+
+
+
+
+## Advanced Generation Control
+
+### Token Selection and Sampling
+
+The process of generating text involves selecting the next token at each step. This selection process can be controlled through various parameters:
+
+1. **Raw Logits**: The initial output probabilities for each token
+2. **Temperature**: Controls randomness in selection (higher = more creative)
+3. **Top-p (Nucleus) Sampling**: Filters to top tokens making up X% of probability mass
+4. **Top-k Filtering**: Limits selection to k most likely tokens
+
+Here's how to configure these parameters:
+
+
+
+
+
+```python
+client.generate(
+ "Write a creative story",
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ top_k=50, # Consider top 50 tokens
+ max_new_tokens=100, # Maximum length
+ repetition_penalty=1.1, # Reduce repetition
+)
+```
+
+
+
+```python
+# Via OpenAI API compatibility
+response = client.completions.create(
+ model="smollm2-1.7b-instruct", # Model name (can be any string for llama.cpp server)
+ prompt="Write a creative story",
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ frequency_penalty=1.1, # Reduce repetition
+ presence_penalty=0.1, # Reduce repetition
+ max_tokens=100, # Maximum length
+)
+
+# Via llama-cpp-python direct access
+output = llm(
+ "Write a creative story",
+ temperature=0.8,
+ top_p=0.95,
+ top_k=50,
+ max_tokens=100,
+ repeat_penalty=1.1,
+)
+```
+
+
+
+```python
+params = SamplingParams(
+ temperature=0.8, # Higher for more creativity
+ top_p=0.95, # Consider top 95% probability mass
+ top_k=50, # Consider top 50 tokens
+ max_tokens=100, # Maximum length
+ presence_penalty=0.1, # Reduce repetition
+)
+llm.generate("Write a creative story", sampling_params=params)
+```
+
+
+
+
+### Controlling Repetition
+
+Both frameworks provide ways to prevent repetitive text generation:
+
+
+
+
+```python
+client.generate(
+ "Write a varied text",
+ repetition_penalty=1.1, # Penalize repeated tokens
+ no_repeat_ngram_size=3, # Prevent 3-gram repetition
+)
+```
+
+
+
+```python
+# Via OpenAI API
+response = client.completions.create(
+ model="smollm2-1.7b-instruct",
+ prompt="Write a varied text",
+ frequency_penalty=1.1, # Penalize frequent tokens
+ presence_penalty=0.8, # Penalize tokens already present
+)
+
+# Via direct library
+output = llm(
+ "Write a varied text",
+ repeat_penalty=1.1, # Penalize repeated tokens
+ frequency_penalty=0.5, # Additional frequency penalty
+ presence_penalty=0.5, # Additional presence penalty
+)
+```
+
+
+
+```python
+params = SamplingParams(
+ presence_penalty=0.1, # Penalize token presence
+ frequency_penalty=0.1, # Penalize token frequency
+)
+```
+
+
+
+
+### Length Control and Stop Sequences
+
+You can control generation length and specify when to stop:
+
+
+
+
+```python
+client.generate(
+ "Generate a short paragraph",
+ max_new_tokens=100,
+ min_new_tokens=10,
+ stop_sequences=["\n\n", "###"],
+)
+```
+
+
+
+```python
+# Via OpenAI API
+response = client.completions.create(
+ model="smollm2-1.7b-instruct",
+ prompt="Generate a short paragraph",
+ max_tokens=100,
+ stop=["\n\n", "###"],
+)
+
+# Via direct library
+output = llm("Generate a short paragraph", max_tokens=100, stop=["\n\n", "###"])
+```
+
+
+
+```python
+params = SamplingParams(
+ max_tokens=100,
+ min_tokens=10,
+ stop=["###", "\n\n"],
+ ignore_eos=False,
+ skip_special_tokens=True,
+)
+```
+
+
+
+
+## Memory Management
+
+Both frameworks implement advanced memory management techniques for efficient inference.
+
+
+
+
+TGI uses Flash Attention 2 and continuous batching:
+
+```sh
+# Docker deployment with memory optimization
+docker run --gpus all -p 8080:80 \
+ --shm-size 1g \
+ ghcr.io/huggingface/text-generation-inference:latest \
+ --model-id HuggingFaceTB/SmolLM2-1.7B-Instruct \
+ --max-batch-total-tokens 8192 \
+ --max-input-length 4096
+```
+
+
+
+llama.cpp uses quantization and optimized memory layout:
+
+```sh
+# Server with memory optimizations
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --host 0.0.0.0 \
+ --port 8080 \
+ -c 2048 \ # Context size
+ --threads 4 \ # CPU threads
+ --n-gpu-layers 32 \ # Use more GPU layers for larger models
+ --mlock \ # Lock memory to prevent swapping
+ --cont-batching # Enable continuous batching
+```
+
+For models too large for your GPU, you can use CPU offloading:
+
+```sh
+./server \
+ -m smollm2-1.7b-instruct.Q4_K_M.gguf \
+ --n-gpu-layers 20 \ # Keep first 20 layers on GPU
+ --threads 8 # Use more CPU threads for CPU layers
+```
+
+
+
+vLLM uses PagedAttention for optimal memory management:
+
+```python
+from vllm.engine.arg_utils import AsyncEngineArgs
+
+engine_args = AsyncEngineArgs(
+ model="HuggingFaceTB/SmolLM2-1.7B-Instruct",
+ gpu_memory_utilization=0.85,
+ max_num_batched_tokens=8192,
+ block_size=16,
+)
+
+llm = LLM(engine_args=engine_args)
+```
+
+
+
+
+## Resources
+
+- [Text Generation Inference Documentation](https://huggingface.co/docs/text-generation-inference)
+- [TGI GitHub Repository](https://github.com/huggingface/text-generation-inference)
+- [vLLM Documentation](https://vllm.readthedocs.io/)
+- [vLLM GitHub Repository](https://github.com/vllm-project/vllm)
+- [PagedAttention Paper](https://arxiv.org/abs/2309.06180)
+- [llama.cpp GitHub Repository](https://github.com/ggerganov/llama.cpp)
+- [llama-cpp-python Repository](https://github.com/abetlen/llama-cpp-python)
\ No newline at end of file
diff --git a/chapters/en/chapter2/9.mdx b/chapters/en/chapter2/9.mdx
new file mode 100644
index 000000000..1a375422a
--- /dev/null
+++ b/chapters/en/chapter2/9.mdx
@@ -0,0 +1,252 @@
+
+
+
+
+# End-of-chapter quiz[[end-of-chapter-quiz]]
+
+
+
+### 1. What is the order of the language modeling pipeline?
+
+
+
+### 2. How many dimensions does the tensor output by the base Transformer model have, and what are they?
+
+
+
+### 3. Which of the following is an example of subword tokenization?
+
+
+
+### 4. What is a model head?
+
+
+
+### 5. What is an AutoModel?
+
+AutoTrain product?"
+ },
+ {
+ text: "An object that returns the correct architecture based on the checkpoint",
+ explain: "Exactly: the AutoModel only needs to know the checkpoint from which to initialize to return the correct architecture.",
+ correct: true
+ },
+ {
+ text: "A model that automatically detects the language used for its inputs to load the correct weights",
+ explain: "While some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the Model Hub to find the best checkpoint for your task!"
+ }
+ ]}
+/>
+
+### 6. What are the techniques to be aware of when batching sequences of different lengths together?
+
+
+
+### 7. What is the point of applying a SoftMax function to the logits output by a sequence classification model?
+
+
+
+### 8. What method is most of the tokenizer API centered around?
+
+encode, as it can encode text into IDs and IDs into predictions",
+ explain: "Wrong! While the encode method does exist on tokenizers, it does not exist on models."
+ },
+ {
+ text: "Calling the tokenizer object directly.",
+ explain: "Exactly! The __call__ method of the tokenizer is a very powerful method which can handle pretty much anything. It is also the method used to retrieve predictions from a model.",
+ correct: true
+ },
+ {
+ text: "pad",
+ explain: "Wrong! Padding is very useful, but it's just one part of the tokenizer API."
+ },
+ {
+ text: "tokenize",
+ explain: "The tokenize method is arguably one of the most useful methods, but it isn't the core of the tokenizer API."
+ }
+ ]}
+/>
+
+### 9. What does the `result` variable contain in this code sample?
+
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+result = tokenizer.tokenize("Hello!")
+```
+
+__call__ or convert_tokens_to_ids method is for!"
+ },
+ {
+ text: "A string containing all of the tokens",
+ explain: "This would be suboptimal, as the goal is to split the string into multiple tokens."
+ }
+ ]}
+/>
+
+### 10. Is there something wrong with the following code?
+
+```py
+from transformers import AutoTokenizer, AutoModel
+
+tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
+model = AutoModel.from_pretrained("gpt2")
+
+encoded = tokenizer("Hey!", return_tensors="pt")
+result = model(**encoded)
+```
+
+
diff --git a/chapters/en/chapter6/4.mdx b/chapters/en/chapter6/4.mdx
index a53611a60..8c7999588 100644
--- a/chapters/en/chapter6/4.mdx
+++ b/chapters/en/chapter6/4.mdx
@@ -104,7 +104,7 @@ Now that we've seen a little of how some different tokenizers process text, we c
## SentencePiece[[sentencepiece]]
-[SentencePiece](https://github.com/google/sentencepiece) is a tokenization algorithm for the preprocessing of text that you can use with any of the models we will see in the next three sections. It considers the text as a sequence of Unicode characters, and replaces spaces with a special character, `▁`. Used in conjunction with the Unigram algorithm (see [section 7](/course/chapter7/7)), it doesn't even require a pre-tokenization step, which is very useful for languages where the space character is not used (like Chinese or Japanese).
+[SentencePiece](https://github.com/google/sentencepiece) is a tokenization algorithm for the preprocessing of text that you can use with any of the models we will see in the next three sections. It considers the text as a sequence of Unicode characters, and replaces spaces with a special character, `▁`. Used in conjunction with the Unigram algorithm (see [section 7](/course/chapter6/7)), it doesn't even require a pre-tokenization step, which is very useful for languages where the space character is not used (like Chinese or Japanese).
The other main feature of SentencePiece is *reversible tokenization*: since there is no special treatment of spaces, decoding the tokens is done simply by concatenating them and replacing the `_`s with spaces -- this results in the normalized text. As we saw earlier, the BERT tokenizer removes repeating spaces, so its tokenization is not reversible.
@@ -120,4 +120,4 @@ Training step | Merges the tokens corresponding to the most common pair | Merges
Learns | Merge rules and a vocabulary | Just a vocabulary | A vocabulary with a score for each token
Encoding | Splits a word into characters and applies the merges learned during training | Finds the longest subword starting from the beginning that is in the vocabulary, then does the same for the rest of the word | Finds the most likely split into tokens, using the scores learned during training
-Now let's dive into BPE!
\ No newline at end of file
+Now let's dive into BPE!
diff --git a/chapters/rum/_toctree.yml b/chapters/rum/_toctree.yml
index bb40acb8b..25730606c 100644
--- a/chapters/rum/_toctree.yml
+++ b/chapters/rum/_toctree.yml
@@ -2,3 +2,27 @@
sections:
- local: chapter0/1
title: Introducere
+
+- title: 1. Modele Transformer
+ sections:
+ - local: chapter1/1
+ title: Introducere
+ - local: chapter1/2
+ title: Procesarea limbajului natural și modelele de limbaj mari
+ - local: chapter1/3
+ title: Transformers, ce pot face?
+ - local: chapter1/4
+ title: Cum funcționează Transformers?
+ - local: chapter1/5
+ title: Modele Encoder
+ - local: chapter1/6
+ title: Modele Decoder
+ - local: chapter1/7
+ title: Modele secvență-la-secvență
+ - local: chapter1/8
+ title: Prejudecăți și limitări
+ - local: chapter1/9
+ title: Rezumat
+ - local: chapter1/10
+ title: Quiz de final de capitol
+ quiz: 1
diff --git a/chapters/rum/chapter1/1.mdx b/chapters/rum/chapter1/1.mdx
new file mode 100644
index 000000000..5d439a10a
--- /dev/null
+++ b/chapters/rum/chapter1/1.mdx
@@ -0,0 +1,119 @@
+# Introducere[[introducere]]
+
+
+
+## Bun venit la 🤗 curs![[bun-venit-la-curs]]
+
+
+
+Acest curs are scopul de a vă învăța despre procesarea limbajelor naturale (NLP) folosind biblioteci din ecosistemul [Hugging Face](https://huggingface.co/) — [🤗 Transformers](https://github.com/huggingface/transformers), [🤗 Datasets](https://github.com/huggingface/datasets), [🤗 Tokenizers](https://github.com/huggingface/tokenizers), și [🤗 Accelerate](https://github.com/huggingface/accelerate) — precum și [Hugging Face Hub](https://huggingface.co/models). Cursul este complet gratuit și nu conține reclame.
+
+## Înțelegerea NLP și a LLM-urilor[[înțelegerea-nlp-și-a-llm-urilor]]
+
+Deși acest curs a fost inițial axat pe NLP (Procesarea Limbajului Natural), el a evoluat pentru a pune accentul pe Large Language Models (LLM-uri), care reprezintă cele mai recente progrese din domeniu.
+
+**Care este diferența?**
+- **NLP (Procesarea Limbajului Natural)** este domeniul mai larg care se concentrează pe permiterea computerelor să înțeleagă, interpreteze și să genereze limbajul uman. NLP include multe tehnici și sarcini, cum ar fi analiza sentimentelor, recunoașterea entităților numite și traducerea automată.
+- **LLM-uri (Modele Mari de Limbaj)** sunt un subset puternic al modelelor NLP, caracterizate prin dimensiuni masive, volume mari de date de antrenament și abilitatea de a îndeplini o gamă largă de sarcini lingvistice cu un antrenament specific minim. Modele precum seriile Llama, GPT sau Claude sunt exemple de LLM-uri care au revoluționat ceea ce este posibil în domeniul NLP.
+
+Pe parcursul acestui curs, vei învăța atât concepte tradiționale din NLP, cât și tehnici de ultimă generație legate de LLM-uri, deoarece înțelegerea fundamentelor NLP este esențială pentru a lucra eficient cu LLM-uri.
+
+## La ce să te aștepți?[[la-ce-sa-te-aștepți]]
+
+Aceasta este o scurtă prezentare a cursului:
+
+
+

+

+
 +
+De asemenea, o listă de [idei de proiecte](https://discuss.huggingface.co/c/course/course-event/25) este disponibilă pe forumuri, în cazul în care doriți să exersați mai mult după ce ați terminat cursul.
+
+- **De unde pot obține codul pentru curs?**
+Pentru fiecare secțiune, faceți clic pe bannerul din partea de sus a paginii pentru a rula codul în Google Colab sau Amazon SageMaker Studio Lab:
+
+
+
+De asemenea, o listă de [idei de proiecte](https://discuss.huggingface.co/c/course/course-event/25) este disponibilă pe forumuri, în cazul în care doriți să exersați mai mult după ce ați terminat cursul.
+
+- **De unde pot obține codul pentru curs?**
+Pentru fiecare secțiune, faceți clic pe bannerul din partea de sus a paginii pentru a rula codul în Google Colab sau Amazon SageMaker Studio Lab:
+
+ +
+Notebook-urile Jupyter care conțin întregul cod al cursului sunt găzduite în repo-ul [`huggingface/notebooks`](https://github.com/huggingface/notebooks). Dacă doriți să le generați local, consultați instrucțiunile din repo-ul [`course`](https://github.com/huggingface/course#-jupyter-notebooks) de pe GitHub.
+
+
+- **Cum pot contribui la curs?**
+Există multe modalități de a contribui la curs! Dacă găsiți o greșeală de tipar sau o eroare, vă rugăm să creați o cerere în repo-ul [`course`](https://github.com/huggingface/course). Dacă doriți să ajutați la traducerea cursului în limba dumneavoastră maternă, consultați instrucțiunile [aici](https://github.com/huggingface/course#translating-the-course-into-your-language).
+
+- **Care au fost alegerile făcute pentru fiecare traducere?**
+Fiecare traducere are un glosar și un fișier `TRANSLATING.txt` care detaliază alegerile care au fost făcute pentru jargonul de Machine Learning etc. Puteți găsi un exemplu în limba germană [aici](https://github.com/huggingface/course/blob/main/chapters/de/TRANSLATING.txt).
+
+
+- **Pot reutiliza acest curs?**
+Desigur! Cursul este distribuit sub licența [Apache 2 license](https://www.apache.org/licenses/LICENSE-2.0.html), o licență permisivă. Aceasta permite reutilizarea materialului cu condiția să acordați credit autorilor, să includeți un link către licență și să menționați eventualele modificări efectuate. Acest lucru poate fi realizat în orice mod rezonabil, atâta timp cât nu implicați în mod fals că licențiatorul susține în mod explicit persoana sau utilizarea dvs. Dacă doriți să citați acest curs, vă rugăm să folosiți următorul formatBibTeX:
+
+```
+@misc{huggingfacecourse,
+ author = {Hugging Face},
+ title = {The Hugging Face Course, 2022},
+ howpublished = "\url{https://huggingface.co/course}",
+ year = {2022},
+ note = "[Online; accessed ]"
+}
+```
+
+## Să începem!
+Sunteți gata să începeți? În acest capitol, veți învăța:
+
+* Cum să utilizați funcția `pipeline()` pentru a rezolva sarcini NLP precum generarea și clasificarea textului
+* Despre arhitectura Transformer
+* Cum să faceți distincția între arhitecturile și cazurile de utilizare ale encoderului, decoderului și encoder-decoder.
diff --git a/chapters/rum/chapter1/10.mdx b/chapters/rum/chapter1/10.mdx
new file mode 100644
index 000000000..4a5ff081f
--- /dev/null
+++ b/chapters/rum/chapter1/10.mdx
@@ -0,0 +1,258 @@
+
+
+# Quiz de sfârșit de capitol[[test-de-sfârșit-de-capitol]]
+
+
+
+Acest capitol a acoperit o mulțime de subiecte! Nu vă faceți griji dacă nu ați înțeles toate detaliile; capitolele următoare vă vor ajuta să înțelegeți cum funcționează lucrurile în mecanismele lor interne.
+
+Mai întâi, însă, să testăm ceea ce ați învățat în acest capitol!
+
+
+### 1. Explorați Hub-ul și căutați checkpoint-ul `roberta-large-mnli`. Ce sarcină îndeplinește acesta?
+
+
+roberta-large-mnli."
+ },
+ {
+ text: "Clasificare de text",
+ explain: "Mai precis, clasifică dacă două propoziții sunt legate logic folosind trei etichete (contradicție, neutru, implicație) — o sarcină numită și inferență în limbaj natural.",
+ correct: true
+ },
+ {
+ text: "Generare de text",
+ explain: "Uitați-vă din nou pe pagina roberta-large-mnli."
+ }
+ ]}
+/>
+
+### 2. Ce va returna următorul cod?
+
+```py
+from transformers import pipeline
+
+ner = pipeline("ner", grouped_entities=True)
+ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+sentiment-analysis."
+ },
+ {
+ text: "Va returna un text generat care completează această propoziție.",
+ explain: "Aceasta este incorect — ar fi un pipeline de
+
+Notebook-urile Jupyter care conțin întregul cod al cursului sunt găzduite în repo-ul [`huggingface/notebooks`](https://github.com/huggingface/notebooks). Dacă doriți să le generați local, consultați instrucțiunile din repo-ul [`course`](https://github.com/huggingface/course#-jupyter-notebooks) de pe GitHub.
+
+
+- **Cum pot contribui la curs?**
+Există multe modalități de a contribui la curs! Dacă găsiți o greșeală de tipar sau o eroare, vă rugăm să creați o cerere în repo-ul [`course`](https://github.com/huggingface/course). Dacă doriți să ajutați la traducerea cursului în limba dumneavoastră maternă, consultați instrucțiunile [aici](https://github.com/huggingface/course#translating-the-course-into-your-language).
+
+- **Care au fost alegerile făcute pentru fiecare traducere?**
+Fiecare traducere are un glosar și un fișier `TRANSLATING.txt` care detaliază alegerile care au fost făcute pentru jargonul de Machine Learning etc. Puteți găsi un exemplu în limba germană [aici](https://github.com/huggingface/course/blob/main/chapters/de/TRANSLATING.txt).
+
+
+- **Pot reutiliza acest curs?**
+Desigur! Cursul este distribuit sub licența [Apache 2 license](https://www.apache.org/licenses/LICENSE-2.0.html), o licență permisivă. Aceasta permite reutilizarea materialului cu condiția să acordați credit autorilor, să includeți un link către licență și să menționați eventualele modificări efectuate. Acest lucru poate fi realizat în orice mod rezonabil, atâta timp cât nu implicați în mod fals că licențiatorul susține în mod explicit persoana sau utilizarea dvs. Dacă doriți să citați acest curs, vă rugăm să folosiți următorul formatBibTeX:
+
+```
+@misc{huggingfacecourse,
+ author = {Hugging Face},
+ title = {The Hugging Face Course, 2022},
+ howpublished = "\url{https://huggingface.co/course}",
+ year = {2022},
+ note = "[Online; accessed ]"
+}
+```
+
+## Să începem!
+Sunteți gata să începeți? În acest capitol, veți învăța:
+
+* Cum să utilizați funcția `pipeline()` pentru a rezolva sarcini NLP precum generarea și clasificarea textului
+* Despre arhitectura Transformer
+* Cum să faceți distincția între arhitecturile și cazurile de utilizare ale encoderului, decoderului și encoder-decoder.
diff --git a/chapters/rum/chapter1/10.mdx b/chapters/rum/chapter1/10.mdx
new file mode 100644
index 000000000..4a5ff081f
--- /dev/null
+++ b/chapters/rum/chapter1/10.mdx
@@ -0,0 +1,258 @@
+
+
+# Quiz de sfârșit de capitol[[test-de-sfârșit-de-capitol]]
+
+
+
+Acest capitol a acoperit o mulțime de subiecte! Nu vă faceți griji dacă nu ați înțeles toate detaliile; capitolele următoare vă vor ajuta să înțelegeți cum funcționează lucrurile în mecanismele lor interne.
+
+Mai întâi, însă, să testăm ceea ce ați învățat în acest capitol!
+
+
+### 1. Explorați Hub-ul și căutați checkpoint-ul `roberta-large-mnli`. Ce sarcină îndeplinește acesta?
+
+
+roberta-large-mnli."
+ },
+ {
+ text: "Clasificare de text",
+ explain: "Mai precis, clasifică dacă două propoziții sunt legate logic folosind trei etichete (contradicție, neutru, implicație) — o sarcină numită și inferență în limbaj natural.",
+ correct: true
+ },
+ {
+ text: "Generare de text",
+ explain: "Uitați-vă din nou pe pagina roberta-large-mnli."
+ }
+ ]}
+/>
+
+### 2. Ce va returna următorul cod?
+
+```py
+from transformers import pipeline
+
+ner = pipeline("ner", grouped_entities=True)
+ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+sentiment-analysis."
+ },
+ {
+ text: "Va returna un text generat care completează această propoziție.",
+ explain: "Aceasta este incorect — ar fi un pipeline de text-generation.",
+ },
+ {
+ text: "Va returna cuvintele care reprezintă persoane, organizații sau locații.",
+ explain: "În plus, cu grouped_entities=True, va grupa împreună cuvintele care aparțin aceleiași entități, precum \"Hugging Face\".",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. Ce ar trebui să înlocuiască ... în acest exemplu de cod?
+
+```py
+from transformers import pipeline
+
+filler = pipeline("fill-mask", model="bert-base-cased")
+result = filler("...")
+```
+
+ has been waiting for you.",
+ explain: "Aceasta este incorect. Verificați cardul modelului bert-base-cased și încercați să identificați greșeala."
+ },
+ {
+ text: "This [MASK] has been waiting for you.",
+ explain: "Corect! Token-ul de mască al acestui model este [MASK].",
+ correct: true
+ },
+ {
+ text: "This man has been waiting for you.",
+ explain: "Aceasta este incorect. Acest pipeline completează cuvinte mascate, deci are nevoie de un token de mască undeva."
+ }
+ ]}
+/>
+
+### 4. De ce nu va funcționa acest cod?
+
+```py
+from transformers import pipeline
+
+classifier = pipeline("zero-shot-classification")
+result = classifier("This is a course about the Transformers library")
+```
+
+candidate_labels=[...].",
+ correct: true
+ },
+ {
+ text: "Acest pipeline necesită mai multe propoziții, nu doar una.",
+ explain: "Aceasta este incorect, deși atunci când este utilizat corespunzător, acest pipeline poate primi o listă de propoziții de procesat (ca toate celelalte pipeline-uri)."
+ },
+ {
+ text: "Biblioteca 🤗 Transformers este defectă, ca de obicei.",
+ explain: "Nu vom onora acest răspuns cu un comentariu!"
+ },
+ {
+ text: "Acest pipeline necesită intrări mai lungi; aceasta este prea scurtă.",
+ explain: "Aceasta este incorect. Rețineți că un text foarte lung va fi trunchiat atunci când este procesat de acest pipeline."
+ }
+ ]}
+/>
+
+### 5. Ce înseamnă „transfer learning"?
+
+
+
+### 6. Adevărat sau fals? De obicei, un model lingvistic nu are nevoie de etichete pentru preinstruire.
+
+auto-supervizată, ceea ce înseamnă că etichetele sunt create automat din intrări (cum ar fi prezicerea următorului cuvânt sau completarea unor cuvinte mascate).",
+ correct: true
+ },
+ {
+ text: "Fals",
+ explain: "Incorect."
+ }
+ ]}
+/>
+
+### 7. Selectați propoziția care descrie cel mai bine termenii „model", „arhitectură" și „greutăți".
+
+
+
+
+### 8. Care dintre aceste tipuri de modele le-ați folosi pentru a completa prompt-urile cu text generat?
+
+
+
+### 9. Care dintre aceste tipuri de modele le-ați folosi pentru a rezuma texte?
+
+
+
+### 10. Care dintre aceste tipuri de modele le-ați utiliza pentru a clasifica intrările de text în funcție de anumite etichete?
+
+
+
+### 11. Ce sursă posibilă poate avea prejudecata observată într-un model?
+
+
diff --git a/chapters/rum/chapter1/2.mdx b/chapters/rum/chapter1/2.mdx
new file mode 100644
index 000000000..77bd5861b
--- /dev/null
+++ b/chapters/rum/chapter1/2.mdx
@@ -0,0 +1,38 @@
+# Procesarea limbajului natural[[procesarea-limbajului-natural]]
+
+
+
+Înainte de a trece la modelele Transformer, haideți să facem o prezentare scurtă despre ce este procesarea limbajului natural și de ce ne interesează.
+
+## Ce este NLP?[[ce-este-nlp]]
+
+NLP este un domeniu al lingvisticii și al învățării automate axat pe înțelegerea a tot ceea ce este legat de limbajul uman. Scopul sarcinilor NLP nu este doar înțelegerea individuală a cuvintelor, ci și capacitatea de a înțelege contextul acelor cuvinte.
+
+În continuare urmează o listă a sarcinilor obișnuite de NLP, cu câteva exemple pentru fiecare:
+
+- **Clasificarea propozițiilor întregi**: Determinarea caracterului unei recenzii, detectarea dacă un e-mail este spam, determinarea dacă o propoziție este corectă gramatical sau dacă două propoziții sunt legate logic sau nu
+- **Clasificarea fiecărui cuvânt dintr-o propoziție**: Identificarea componentelor gramaticale ale unei propoziții (substantiv, verb, adjectiv) sau a entităților nominalizate (persoană, locație, organizație)
+- **Generarea conținutului de text**: Completarea unui prompt cu text generat automat, completarea spațiilor goale dintr-un text cu cuvinte mascate
+- **Extragerea unui răspuns dintr-un text**: Având o întrebare și un context, se extrage răspunsul la întrebare pe baza informațiilor furnizate în context
+- **Generarea unei propoziții noi dintr-un text de intrare**: Traducerea unui text într-o altă limbă, rezumarea textului
+
+NLP nu se limitează însă la textul scris. De asemenea, NLP abordează provocări complexe în domeniul recunoașterii vorbirii și al viziunii computerizate, cum ar fi generarea unei transcrieri a unui fragment audio sau a unei descrieri a unei imagini.
+
+## Ascensiunea a Large Language Models (LLM-uri)[[rise-of-llms]]
+
+În ultimii ani, domeniul NLP a fost revoluționat de Large Language Models (LLM-uri). Aceste modele, care includ arhitecturi precum GPT (Generative Pre-trained Transformer) și [Llama](https://huggingface.co/meta-llama), au transformat ceea ce este posibil în procesarea limbajului.
+
+LLM-urile se caracterizează prin:
+- **Mărime**: Conțin milioane, miliarde sau chiar sute de miliarde de parametri
+- **Capacități generale**: Pot realiza multiple sarcini fără antrenament specific pentru fiecare sarcină
+- **Învățare în context**: Pot învăța din exemplele oferite în prompt
+- **Abilități emergente**: Pe măsură ce aceste modele cresc în dimensiune, demonstrează capacități care nu au fost programate sau anticipate în mod explicit
+
+Apariția LLM-urilor a schimbat paradigma de la construirea unor modele specializate pentru sarcini NLP specifice la utilizarea unui singur model mare care poate fi direcționat prin prompturi sau ajustat pentru a aborda o gamă largă de sarcini lingvistice. Acest lucru a făcut procesarea sofisticată a limbajului mai accesibilă, dar a introdus și noi provocări în domenii precum eficiența, etica și implementarea.
+
+## De ce este o provocare?[[de-ce-este-o-provocare]]
+
+Computerele nu procesează informațiile în același mod ca oamenii. De exemplu, atunci când citim propoziția „Mi-e foame”, îi putem înțelege cu ușurință semnificația. În mod similar, având în vedere două propoziții precum „Mi-e foame” și „Sunt trist”, suntem capabili să determinăm cu ușurință cât de asemănătoare sunt acestea. Pentru modelele de învățare automată (ML), astfel de sarcini sunt mai dificile. Textul trebuie prelucrat într-un mod care să permită modelului să învețe din conținutul său. Și deoarece limbajul este complex, trebuie să ne gândim cu atenție la modul optim de a realiza această procesare. Au fost efectuate numeroase cercetări cu privire la modul de reprezentare a textului și vom analiza câteva metode în capitolul următor.
diff --git a/chapters/rum/chapter1/3.mdx b/chapters/rum/chapter1/3.mdx
new file mode 100644
index 000000000..f5d890f1e
--- /dev/null
+++ b/chapters/rum/chapter1/3.mdx
@@ -0,0 +1,326 @@
+# Ce pot face modelele Transformer[[ce-pot-face-modelele-transformer]]
+
+
+
+În această parte, vom explora ce pot face modelele Transformer și vom folosi primul nostru instrument din biblioteca 🤗 Transformers: funcția `pipeline()`.
+
+
+👀 Vedeți butonul Open in Colab din dreapta sus? Faceți clic pe el pentru a deschide un notebook Google Colab cu toate exemplele de cod din această secțiune. Acest buton va fi prezent în orice secțiune care conține exemple de cod.
+Dacă doriți să executați exemplele local, vă recomandăm să aruncați o privire la setup.
+
+
+## Modelele Transformer sunt peste tot![[modelele-transformer-sunt-peste-tot]]
+
+Modelele Transformer sunt utilizate pentru a rezolva toate tipurile de sarcini NLP, precum cele menționate în secțiunea anterioară. Iată câteva dintre companiile și organizațiile care utilizează modelele Hugging Face și Transformer, care de asemenea contribuie la dezvoltarea comunității prin partajarea modelelor lor:
+
+ +
+Biblioteca [🤗 Transformers](https://github.com/huggingface/transformers) oferă funcționalitatea de a crea și utiliza aceste modele partajate. [Model Hub](https://huggingface.co/models) conține mii de modele preinstruite pe care oricine le poate descărca și utiliza. De asemenea, vă puteți încărca propriile modele pe Hub!
+
+
+⚠️ Hub-ul Hugging Face nu este limitat la modelele Transformer. Oricine poate partaja orice fel de modele sau seturi de date pe care le dorește! Creați un cont huggingface.co pentru a beneficia de toate funcțiile disponibile!
+
+
+Înainte de a analiza funcționarea internă a modelelor Transformer , să ne oprim asupra unor exemple privind modul în care acestea pot fi utilizate pentru a rezolva unele probleme interesante de NLP.
+
+## Lucrul cu pipelines[[lucrul-cu-pipelines]]
+
+
+
+Obiectul cel mai elementar din biblioteca 🤗 Transformers este funcția `pipeline()`. Aceasta conectează un model cu etapele sale necesare de preprocesare și postprocesare, permițându-ne să introducem direct orice text și să obținem un răspuns inteligibil:
+
+```python
+from transformers import pipeline
+
+classifier = pipeline("sentiment-analysis")
+classifier("I've been waiting for a HuggingFace course my whole life.")
+```
+
+```python out
+[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
+```
+
+Putem adăuga chiar și mai multe propoziții!
+
+```python
+classifier(
+ ["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
+)
+```
+
+```python out
+[{'label': 'POSITIVE', 'score': 0.9598047137260437},
+ {'label': 'NEGATIVE', 'score': 0.9994558095932007}]
+```
+
+În mod implicit, acest pipeline selectează un anumit model preinstruit care a fost ajustat pentru a analiza emoțiile dintr-un text în limba engleză. Modelul este descărcat și pus în cache atunci când creați obiectul `classifier`. Dacă rulați din nou comanda, modelul din memoria cache va fi utilizat în locul acestuia și nu este nevoie să descărcați din nou modelul.
+
+Atunci când transmiteți un text către un pipeline, sunt necesari trei pași:
+
+1. Textul este preprocesat într-un format pe care modelul îl poate înțelege.
+2. Datele de intrare preprocesate sunt transmise modelului.
+3. Predicțiile modelului sunt postprocesate, astfel încât să le puteți înțelege.
+
+
+Unele dintre [pipeline-urile disponibile](https://huggingface.co/transformers/main_classes/pipelines) în prezent sunt:
+
+- `feature-extraction` (obține reprezentarea vectorială a unui text)
+- `fill-mask`
+- `ner` (named entity recognition/recunoașterea entităților numite)
+- `question-answering`
+- `sentiment-analysis`
+- `summarization`
+- `text-generation`
+- `translation`
+- `zero-shot-classification`
+
+Să aruncăm o privire la câteva dintre ele!
+
+## Zero-shot classification[[zero-shot-classification]]
+
+Vom începe prin a aborda o sarcină mai dificilă în care trebuie să clasificăm texte care nu au fost etichetate. Acesta este un scenariu comun în proiectele din lumea reală, deoarece adnotarea textului este de obicei costisitoare în timp și necesită expertiză în domeniu. Pentru acest caz de utilizare, pipeline-ul `zero-shot-classification` este foarte puternic: vă permite să specificați ce etichete să utilizați pentru clasificare, astfel încât să nu fie nevoie să vă bazați pe etichetele modelului preinstruit. Ați văzut deja cum modelul poate clasifica o propoziție ca fiind pozitivă sau negativă folosind aceste două etichete - dar poate, de asemenea, clasifica textul folosind orice alt set de etichete doriți.
+
+```python
+from transformers import pipeline
+
+classifier = pipeline("zero-shot-classification")
+classifier(
+ "This is a course about the Transformers library",
+ candidate_labels=["education", "politics", "business"],
+)
+```
+
+```python out
+{'sequence': 'This is a course about the Transformers library',
+ 'labels': ['education', 'business', 'politics'],
+ 'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
+```
+
+Acest pipeline se numește _zero-shot_ deoarece nu trebuie să reglați modelul pe datele dvs. pentru a o utiliza. Aceasta poate returna direct scoruri de probabilitate pentru orice listă de etichete doriți!
+
+
+
+✏️ **Încercați** Jucați-vă cu propriile secvențe și etichete și vedeți cum se comportă modelul.
+
+
+
+
+## Text generation[[text-generation]]
+
+Să vedem acum cum se utilizează un pipeline pentru a genera un text. Ideea principală aici este că furnizați o solicitare, iar modelul o va completa automat prin generarea textului rămas. Acest lucru este similar cu funcția de text previzibil care se găsește pe multe telefoane. Generarea textului implică caracter aleatoriu, deci este normal să nu obțineți aceleași rezultate ca cele prezentate mai jos.
+
+```python
+from transformers import pipeline
+
+generator = pipeline("text-generation")
+generator("In this course, we will teach you how to")
+```
+
+```python out
+[{'generated_text': 'In this course, we will teach you how to understand and use '
+ 'data flow and data interchange when handling user data. We '
+ 'will be working with one or more of the most commonly used '
+ 'data flows — data flows of various types, as seen by the '
+ 'HTTP'}]
+```
+
+Puteți controla câte secvențe diferite sunt generate cu argumentul `num_return_sequences` și lungimea totală a textului de ieșire cu argumentul `max_length`.
+
+
+
+✏️ **Încercați!** Utilizați argumentele `num_return_sequences` și `max_length` pentru a genera două propoziții a câte 15 cuvinte fiecare.
+
+
+
+
+## Utilizarea oricărui model de pe Hub într-un pipeline[[utilizarea-oricărui-model-de-pe-hub-într-un-pipeline]]
+
+Exemplele anterioare au utilizat modelul implicit pentru sarcina în cauză, dar puteți alege, de asemenea, un anumit model din Hub pentru a-l utiliza într-un pipeline pentru o sarcină specifică - de exemplu, generarea de text. Accesați [Model Hub](https://huggingface.co/models) și faceți clic pe eticheta corespunzătoare din stânga pentru a afișa numai modelele acceptate pentru sarcina respectivă. Ar trebui să ajungeți la o pagină precum [aceasta](https://huggingface.co/models?pipeline_tag=text-generation).
+
+Să încercăm modelul [`distilgpt2`](https://huggingface.co/distilgpt2)! Iată cum să îl puteți încărca în același pipeline ca înainte:
+
+```python
+from transformers import pipeline
+
+generator = pipeline("text-generation", model="distilgpt2")
+generator(
+ "In this course, we will teach you how to",
+ max_length=30,
+ num_return_sequences=2,
+)
+```
+
+```python out
+[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
+ 'move your mental and physical capabilities to your advantage.'},
+ {'generated_text': 'In this course, we will teach you how to become an expert and '
+ 'practice realtime, and with a hands on experience on both real '
+ 'time and real'}]
+```
+
+Puteți să vă îmbunătățiți căutarea unui model făcând clic pe etichetele de limbaj și să alegând un model care să genereze text într-o altă limbă. Model Hub conține chiar și puncte de control pentru modele multilingve care acceptă mai multe limbi.
+
+După ce selectați un model făcând clic pe el, veți vedea că există un widget care vă permite să îl încercați direct online. În acest fel, puteți testa rapid capacitățile modelului înainte de a-l descărca.
+
+
+
+✏️ ** Încercați!** Utilizați filtrele pentru a găsi un model de generare a textului pentru o altă limbă. Nu ezitați să explorați widget-ul și să îl utilizați într-un pipeline!
+
+
+
+### API-ul de inferență[[api-ul-de-inferență]]
+
+Toate modelele pot fi testate direct prin browser utilizând API-ul de inferență, care este disponibil pe site-ul Hugging Face [website] (https://huggingface.co/). Puteți interacționa cu modelul direct pe această pagină introducând text personalizat și urmărind cum procesează datele de intrare.
+
+API-ul de inferență care alimentează widget-ul este, de asemenea, disponibil ca produs plătit, ceea ce este util dacă aveți nevoie de el pentru fluxurile dvs. de lucru. Consultați [pagina de prețuri](https://huggingface.co/pricing) pentru mai multe detalii.
+
+## Mask filling[[mask-filling]]
+
+Următorul pipeline pe care il veți încerca este `fill-mask`. Ideea acestei sarcini este de a completa golurile dintr-un text dat:
+
+```python
+from transformers import pipeline
+
+unmasker = pipeline("fill-mask")
+unmasker("This course will teach you all about models.", top_k=2)
+```
+
+```python out
+[{'sequence': 'This course will teach you all about mathematical models.',
+ 'score': 0.19619831442832947,
+ 'token': 30412,
+ 'token_str': ' mathematical'},
+ {'sequence': 'This course will teach you all about computational models.',
+ 'score': 0.04052725434303284,
+ 'token': 38163,
+ 'token_str': ' computational'}]
+```
+
+Argumentul `top_k` controlează câte posibilități doriți să fie afișate. Rețineți că aici modelul completează cuvântul special ``, care este adesea denumit *mask token*. Alte modele de umplere a măștii ar putea avea token-uri de mască diferite, astfel încât este întotdeauna bine să verificați cuvântul de mască adecvat atunci când explorați alte modele. O modalitate de verificare este să vă uitați la cuvântul mască utilizat în widget.
+
+
+
+✏️ **Încercați!** Căutați modelul `bert-base-cased` pe Hub și identificați-i cuvântul mască în widget-ul Inference API. Ce prezice acest model pentru propoziția din exemplul nostru `pipeline` de mai sus?
+
+
+
+## Named entity recognition[[named-entity-recognition]]
+
+Named Entity Recognition (NER) este o sarcină în care modelul trebuie să găsească care părți din textul de intrare corespund unor entități precum persoane, locații sau organizații. Să ne uităm la un exemplu:
+
+```python
+from transformers import pipeline
+
+ner = pipeline("ner", grouped_entities=True)
+ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
+]
+```
+
+Aici, modelul a identificat corect că Sylvain este o persoană (PER), Hugging Face o organizație (ORG), iar Brooklyn o locație (LOC).
+
+Trecem opțiunea `grouped_entities=True` în funcția de creare a pipeline-ului pentru a-i spune pipeline-ului să regrupeze părțile propoziției care corespund aceleiași entități: aici, modelul a grupat corect „Hugging” și „Face” ca o singură organizație, chiar dacă numele este format din mai multe cuvinte. De fapt, după cum vom vedea în capitolul următor, preprocesarea chiar împarte unele cuvinte în părți mai mici. De exemplu, `Sylvain` este împărțit în patru părți: `S`, `##yl`, `##va`, și `##in`. În etapa de postprocesare, pipeline-ul a reușit să regrupeze aceste părți.
+
+
+
+✏️ **Încercați!** Căutați în Hub-ul de modele un model capabil să facă etichetarea părții de vorbire (de obicei abreviată ca POS) în limba engleză. Ce prezice acest model pentru propoziția din exemplul de mai sus?
+
+
+
+## Question answering[[question-answering]]
+
+Pipeline-ul "question-answering" răspunde la întrebări folosind informații dintr-un context dat:
+
+```python
+from transformers import pipeline
+
+question_answerer = pipeline("question-answering")
+question_answerer(
+ question="Where do I work?",
+ context="My name is Sylvain and I work at Hugging Face in Brooklyn",
+)
+```
+
+```python out
+{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
+```
+
+Rețineți că acest pipeline funcționează prin extragerea informațiilor din contextul furnizat; el nu generează răspunsul.
+
+## Summarization[[summarization]]
+
+Rezumarea este sarcina de a reduce un text într-un altul mai scurt, păstrând toate (sau majoritatea) aspectelor importante menționate în el. Iată un exemplu:
+
+```python
+from transformers import pipeline
+
+summarizer = pipeline("summarization")
+summarizer(
+ """
+ America has changed dramatically during recent years. Not only has the number of
+ graduates in traditional engineering disciplines such as mechanical, civil,
+ electrical, chemical, and aeronautical engineering declined, but in most of
+ the premier American universities engineering curricula now concentrate on
+ and encourage largely the study of engineering science. As a result, there
+ are declining offerings in engineering subjects dealing with infrastructure,
+ the environment, and related issues, and greater concentration on high
+ technology subjects, largely supporting increasingly complex scientific
+ developments. While the latter is important, it should not be at the expense
+ of more traditional engineering.
+
+ Rapidly developing economies such as China and India, as well as other
+ industrial countries in Europe and Asia, continue to encourage and advance
+ the teaching of engineering. Both China and India, respectively, graduate
+ six and eight times as many traditional engineers as does the United States.
+ Other industrial countries at minimum maintain their output, while America
+ suffers an increasingly serious decline in the number of engineering graduates
+ and a lack of well-educated engineers.
+"""
+)
+```
+
+```python out
+[{'summary_text': ' America has changed dramatically during recent years . The '
+ 'number of engineering graduates in the U.S. has declined in '
+ 'traditional engineering disciplines such as mechanical, civil '
+ ', electrical, chemical, and aeronautical engineering . Rapidly '
+ 'developing economies such as China and India, as well as other '
+ 'industrial countries in Europe and Asia, continue to encourage '
+ 'and advance engineering .'}]
+```
+
+La fel ca în cazul generării de text, puteți specifica o lungime `max_length` sau `min_length` pentru rezultat.
+
+## Translation[[translation]]
+
+Pentru traducere, puteți utiliza un model predefinit dacă introduceți o combinație de limbi în numele sarcinii (cum ar fi `„translation_en_to_fr”`), dar cel mai simplu este să alegeți modelul pe care doriți să îl utilizați în [Model Hub](https://huggingface.co/models). Aici vom încerca să traducem din franceză în engleză:
+
+```python
+from transformers import pipeline
+
+translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
+translator("Ce cours est produit par Hugging Face.")
+```
+
+```python out
+[{'translation_text': 'This course is produced by Hugging Face.'}]
+```
+
+Ca și în cazul generării și rezumării textului, puteți specifica `max_length` sau `min_length` pentru rezultat.
+
+
+✏️ **Încercați!** Căutați modele de traducere în alte limbi și încercați să traduceți propoziția anterioară în câteva limbi diferite.
+
+
+
+Pipeline-urile prezentate până în acest moment au în principal scop demonstrativ. Ele au fost programate pentru sarcini specifice și nu pot efectua variații ale acestora. În capitolul următor, veți afla ce se află în interiorul unei funcții `pipeline()` și cum să îi personalizați comportamentul.
\ No newline at end of file
diff --git a/chapters/rum/chapter1/4.mdx b/chapters/rum/chapter1/4.mdx
new file mode 100644
index 000000000..865bfaf2c
--- /dev/null
+++ b/chapters/rum/chapter1/4.mdx
@@ -0,0 +1,178 @@
+# Cum funcționează Transformers?[[cum-funcționează-transformers]]
+
+
+
+În această secțiune, vom analiza arhitectura modelelor Transformer.
+
+## Un pic despre istoria modelelor Transformer[[un-pic-despre-istoria-modelelor-transformer]]
+
+Iată câteva puncte de referință în (scurta) istorie a modelelor Transformer:
+
+
+
+Biblioteca [🤗 Transformers](https://github.com/huggingface/transformers) oferă funcționalitatea de a crea și utiliza aceste modele partajate. [Model Hub](https://huggingface.co/models) conține mii de modele preinstruite pe care oricine le poate descărca și utiliza. De asemenea, vă puteți încărca propriile modele pe Hub!
+
+
+⚠️ Hub-ul Hugging Face nu este limitat la modelele Transformer. Oricine poate partaja orice fel de modele sau seturi de date pe care le dorește! Creați un cont huggingface.co pentru a beneficia de toate funcțiile disponibile!
+
+
+Înainte de a analiza funcționarea internă a modelelor Transformer , să ne oprim asupra unor exemple privind modul în care acestea pot fi utilizate pentru a rezolva unele probleme interesante de NLP.
+
+## Lucrul cu pipelines[[lucrul-cu-pipelines]]
+
+
+
+Obiectul cel mai elementar din biblioteca 🤗 Transformers este funcția `pipeline()`. Aceasta conectează un model cu etapele sale necesare de preprocesare și postprocesare, permițându-ne să introducem direct orice text și să obținem un răspuns inteligibil:
+
+```python
+from transformers import pipeline
+
+classifier = pipeline("sentiment-analysis")
+classifier("I've been waiting for a HuggingFace course my whole life.")
+```
+
+```python out
+[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
+```
+
+Putem adăuga chiar și mai multe propoziții!
+
+```python
+classifier(
+ ["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
+)
+```
+
+```python out
+[{'label': 'POSITIVE', 'score': 0.9598047137260437},
+ {'label': 'NEGATIVE', 'score': 0.9994558095932007}]
+```
+
+În mod implicit, acest pipeline selectează un anumit model preinstruit care a fost ajustat pentru a analiza emoțiile dintr-un text în limba engleză. Modelul este descărcat și pus în cache atunci când creați obiectul `classifier`. Dacă rulați din nou comanda, modelul din memoria cache va fi utilizat în locul acestuia și nu este nevoie să descărcați din nou modelul.
+
+Atunci când transmiteți un text către un pipeline, sunt necesari trei pași:
+
+1. Textul este preprocesat într-un format pe care modelul îl poate înțelege.
+2. Datele de intrare preprocesate sunt transmise modelului.
+3. Predicțiile modelului sunt postprocesate, astfel încât să le puteți înțelege.
+
+
+Unele dintre [pipeline-urile disponibile](https://huggingface.co/transformers/main_classes/pipelines) în prezent sunt:
+
+- `feature-extraction` (obține reprezentarea vectorială a unui text)
+- `fill-mask`
+- `ner` (named entity recognition/recunoașterea entităților numite)
+- `question-answering`
+- `sentiment-analysis`
+- `summarization`
+- `text-generation`
+- `translation`
+- `zero-shot-classification`
+
+Să aruncăm o privire la câteva dintre ele!
+
+## Zero-shot classification[[zero-shot-classification]]
+
+Vom începe prin a aborda o sarcină mai dificilă în care trebuie să clasificăm texte care nu au fost etichetate. Acesta este un scenariu comun în proiectele din lumea reală, deoarece adnotarea textului este de obicei costisitoare în timp și necesită expertiză în domeniu. Pentru acest caz de utilizare, pipeline-ul `zero-shot-classification` este foarte puternic: vă permite să specificați ce etichete să utilizați pentru clasificare, astfel încât să nu fie nevoie să vă bazați pe etichetele modelului preinstruit. Ați văzut deja cum modelul poate clasifica o propoziție ca fiind pozitivă sau negativă folosind aceste două etichete - dar poate, de asemenea, clasifica textul folosind orice alt set de etichete doriți.
+
+```python
+from transformers import pipeline
+
+classifier = pipeline("zero-shot-classification")
+classifier(
+ "This is a course about the Transformers library",
+ candidate_labels=["education", "politics", "business"],
+)
+```
+
+```python out
+{'sequence': 'This is a course about the Transformers library',
+ 'labels': ['education', 'business', 'politics'],
+ 'scores': [0.8445963859558105, 0.111976258456707, 0.043427448719739914]}
+```
+
+Acest pipeline se numește _zero-shot_ deoarece nu trebuie să reglați modelul pe datele dvs. pentru a o utiliza. Aceasta poate returna direct scoruri de probabilitate pentru orice listă de etichete doriți!
+
+
+
+✏️ **Încercați** Jucați-vă cu propriile secvențe și etichete și vedeți cum se comportă modelul.
+
+
+
+
+## Text generation[[text-generation]]
+
+Să vedem acum cum se utilizează un pipeline pentru a genera un text. Ideea principală aici este că furnizați o solicitare, iar modelul o va completa automat prin generarea textului rămas. Acest lucru este similar cu funcția de text previzibil care se găsește pe multe telefoane. Generarea textului implică caracter aleatoriu, deci este normal să nu obțineți aceleași rezultate ca cele prezentate mai jos.
+
+```python
+from transformers import pipeline
+
+generator = pipeline("text-generation")
+generator("In this course, we will teach you how to")
+```
+
+```python out
+[{'generated_text': 'In this course, we will teach you how to understand and use '
+ 'data flow and data interchange when handling user data. We '
+ 'will be working with one or more of the most commonly used '
+ 'data flows — data flows of various types, as seen by the '
+ 'HTTP'}]
+```
+
+Puteți controla câte secvențe diferite sunt generate cu argumentul `num_return_sequences` și lungimea totală a textului de ieșire cu argumentul `max_length`.
+
+
+
+✏️ **Încercați!** Utilizați argumentele `num_return_sequences` și `max_length` pentru a genera două propoziții a câte 15 cuvinte fiecare.
+
+
+
+
+## Utilizarea oricărui model de pe Hub într-un pipeline[[utilizarea-oricărui-model-de-pe-hub-într-un-pipeline]]
+
+Exemplele anterioare au utilizat modelul implicit pentru sarcina în cauză, dar puteți alege, de asemenea, un anumit model din Hub pentru a-l utiliza într-un pipeline pentru o sarcină specifică - de exemplu, generarea de text. Accesați [Model Hub](https://huggingface.co/models) și faceți clic pe eticheta corespunzătoare din stânga pentru a afișa numai modelele acceptate pentru sarcina respectivă. Ar trebui să ajungeți la o pagină precum [aceasta](https://huggingface.co/models?pipeline_tag=text-generation).
+
+Să încercăm modelul [`distilgpt2`](https://huggingface.co/distilgpt2)! Iată cum să îl puteți încărca în același pipeline ca înainte:
+
+```python
+from transformers import pipeline
+
+generator = pipeline("text-generation", model="distilgpt2")
+generator(
+ "In this course, we will teach you how to",
+ max_length=30,
+ num_return_sequences=2,
+)
+```
+
+```python out
+[{'generated_text': 'In this course, we will teach you how to manipulate the world and '
+ 'move your mental and physical capabilities to your advantage.'},
+ {'generated_text': 'In this course, we will teach you how to become an expert and '
+ 'practice realtime, and with a hands on experience on both real '
+ 'time and real'}]
+```
+
+Puteți să vă îmbunătățiți căutarea unui model făcând clic pe etichetele de limbaj și să alegând un model care să genereze text într-o altă limbă. Model Hub conține chiar și puncte de control pentru modele multilingve care acceptă mai multe limbi.
+
+După ce selectați un model făcând clic pe el, veți vedea că există un widget care vă permite să îl încercați direct online. În acest fel, puteți testa rapid capacitățile modelului înainte de a-l descărca.
+
+
+
+✏️ ** Încercați!** Utilizați filtrele pentru a găsi un model de generare a textului pentru o altă limbă. Nu ezitați să explorați widget-ul și să îl utilizați într-un pipeline!
+
+
+
+### API-ul de inferență[[api-ul-de-inferență]]
+
+Toate modelele pot fi testate direct prin browser utilizând API-ul de inferență, care este disponibil pe site-ul Hugging Face [website] (https://huggingface.co/). Puteți interacționa cu modelul direct pe această pagină introducând text personalizat și urmărind cum procesează datele de intrare.
+
+API-ul de inferență care alimentează widget-ul este, de asemenea, disponibil ca produs plătit, ceea ce este util dacă aveți nevoie de el pentru fluxurile dvs. de lucru. Consultați [pagina de prețuri](https://huggingface.co/pricing) pentru mai multe detalii.
+
+## Mask filling[[mask-filling]]
+
+Următorul pipeline pe care il veți încerca este `fill-mask`. Ideea acestei sarcini este de a completa golurile dintr-un text dat:
+
+```python
+from transformers import pipeline
+
+unmasker = pipeline("fill-mask")
+unmasker("This course will teach you all about models.", top_k=2)
+```
+
+```python out
+[{'sequence': 'This course will teach you all about mathematical models.',
+ 'score': 0.19619831442832947,
+ 'token': 30412,
+ 'token_str': ' mathematical'},
+ {'sequence': 'This course will teach you all about computational models.',
+ 'score': 0.04052725434303284,
+ 'token': 38163,
+ 'token_str': ' computational'}]
+```
+
+Argumentul `top_k` controlează câte posibilități doriți să fie afișate. Rețineți că aici modelul completează cuvântul special ``, care este adesea denumit *mask token*. Alte modele de umplere a măștii ar putea avea token-uri de mască diferite, astfel încât este întotdeauna bine să verificați cuvântul de mască adecvat atunci când explorați alte modele. O modalitate de verificare este să vă uitați la cuvântul mască utilizat în widget.
+
+
+
+✏️ **Încercați!** Căutați modelul `bert-base-cased` pe Hub și identificați-i cuvântul mască în widget-ul Inference API. Ce prezice acest model pentru propoziția din exemplul nostru `pipeline` de mai sus?
+
+
+
+## Named entity recognition[[named-entity-recognition]]
+
+Named Entity Recognition (NER) este o sarcină în care modelul trebuie să găsească care părți din textul de intrare corespund unor entități precum persoane, locații sau organizații. Să ne uităm la un exemplu:
+
+```python
+from transformers import pipeline
+
+ner = pipeline("ner", grouped_entities=True)
+ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
+]
+```
+
+Aici, modelul a identificat corect că Sylvain este o persoană (PER), Hugging Face o organizație (ORG), iar Brooklyn o locație (LOC).
+
+Trecem opțiunea `grouped_entities=True` în funcția de creare a pipeline-ului pentru a-i spune pipeline-ului să regrupeze părțile propoziției care corespund aceleiași entități: aici, modelul a grupat corect „Hugging” și „Face” ca o singură organizație, chiar dacă numele este format din mai multe cuvinte. De fapt, după cum vom vedea în capitolul următor, preprocesarea chiar împarte unele cuvinte în părți mai mici. De exemplu, `Sylvain` este împărțit în patru părți: `S`, `##yl`, `##va`, și `##in`. În etapa de postprocesare, pipeline-ul a reușit să regrupeze aceste părți.
+
+
+
+✏️ **Încercați!** Căutați în Hub-ul de modele un model capabil să facă etichetarea părții de vorbire (de obicei abreviată ca POS) în limba engleză. Ce prezice acest model pentru propoziția din exemplul de mai sus?
+
+
+
+## Question answering[[question-answering]]
+
+Pipeline-ul "question-answering" răspunde la întrebări folosind informații dintr-un context dat:
+
+```python
+from transformers import pipeline
+
+question_answerer = pipeline("question-answering")
+question_answerer(
+ question="Where do I work?",
+ context="My name is Sylvain and I work at Hugging Face in Brooklyn",
+)
+```
+
+```python out
+{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
+```
+
+Rețineți că acest pipeline funcționează prin extragerea informațiilor din contextul furnizat; el nu generează răspunsul.
+
+## Summarization[[summarization]]
+
+Rezumarea este sarcina de a reduce un text într-un altul mai scurt, păstrând toate (sau majoritatea) aspectelor importante menționate în el. Iată un exemplu:
+
+```python
+from transformers import pipeline
+
+summarizer = pipeline("summarization")
+summarizer(
+ """
+ America has changed dramatically during recent years. Not only has the number of
+ graduates in traditional engineering disciplines such as mechanical, civil,
+ electrical, chemical, and aeronautical engineering declined, but in most of
+ the premier American universities engineering curricula now concentrate on
+ and encourage largely the study of engineering science. As a result, there
+ are declining offerings in engineering subjects dealing with infrastructure,
+ the environment, and related issues, and greater concentration on high
+ technology subjects, largely supporting increasingly complex scientific
+ developments. While the latter is important, it should not be at the expense
+ of more traditional engineering.
+
+ Rapidly developing economies such as China and India, as well as other
+ industrial countries in Europe and Asia, continue to encourage and advance
+ the teaching of engineering. Both China and India, respectively, graduate
+ six and eight times as many traditional engineers as does the United States.
+ Other industrial countries at minimum maintain their output, while America
+ suffers an increasingly serious decline in the number of engineering graduates
+ and a lack of well-educated engineers.
+"""
+)
+```
+
+```python out
+[{'summary_text': ' America has changed dramatically during recent years . The '
+ 'number of engineering graduates in the U.S. has declined in '
+ 'traditional engineering disciplines such as mechanical, civil '
+ ', electrical, chemical, and aeronautical engineering . Rapidly '
+ 'developing economies such as China and India, as well as other '
+ 'industrial countries in Europe and Asia, continue to encourage '
+ 'and advance engineering .'}]
+```
+
+La fel ca în cazul generării de text, puteți specifica o lungime `max_length` sau `min_length` pentru rezultat.
+
+## Translation[[translation]]
+
+Pentru traducere, puteți utiliza un model predefinit dacă introduceți o combinație de limbi în numele sarcinii (cum ar fi `„translation_en_to_fr”`), dar cel mai simplu este să alegeți modelul pe care doriți să îl utilizați în [Model Hub](https://huggingface.co/models). Aici vom încerca să traducem din franceză în engleză:
+
+```python
+from transformers import pipeline
+
+translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
+translator("Ce cours est produit par Hugging Face.")
+```
+
+```python out
+[{'translation_text': 'This course is produced by Hugging Face.'}]
+```
+
+Ca și în cazul generării și rezumării textului, puteți specifica `max_length` sau `min_length` pentru rezultat.
+
+
+✏️ **Încercați!** Căutați modele de traducere în alte limbi și încercați să traduceți propoziția anterioară în câteva limbi diferite.
+
+
+
+Pipeline-urile prezentate până în acest moment au în principal scop demonstrativ. Ele au fost programate pentru sarcini specifice și nu pot efectua variații ale acestora. În capitolul următor, veți afla ce se află în interiorul unei funcții `pipeline()` și cum să îi personalizați comportamentul.
\ No newline at end of file
diff --git a/chapters/rum/chapter1/4.mdx b/chapters/rum/chapter1/4.mdx
new file mode 100644
index 000000000..865bfaf2c
--- /dev/null
+++ b/chapters/rum/chapter1/4.mdx
@@ -0,0 +1,178 @@
+# Cum funcționează Transformers?[[cum-funcționează-transformers]]
+
+
+
+În această secțiune, vom analiza arhitectura modelelor Transformer.
+
+## Un pic despre istoria modelelor Transformer[[un-pic-despre-istoria-modelelor-transformer]]
+
+Iată câteva puncte de referință în (scurta) istorie a modelelor Transformer:
+
+
+

+

+
+

+

+
+

+

+
+

+
+

+

+
+

+

+
+

+

+
+

+

+
+

+

+
+
+
+
+