如果你正在开发 AI Agent,大概率已经体验过这种崩溃时刻:
- 周一测试,Agent 表现完美 ✨
- 周三上线,Agent 开始发疯 🤯
- 周五回滚,产品经理摔杯子 💥
欢迎来到 Agent 开发的"薛定谔测试"世界:同样的输入,今天对明天错,上午行下午崩。
这篇文档基于 Anthropic 的万字长文,加上我们的理解和吐槽,带你系统性地搞定 Agent 评估这个"玄学"。
- 1. 为什么传统测试方法全线崩溃
- 2. 重新认识评估系统
- 3. 三种评分器的正确打开方式
- 4. 四类 Agent 的评估秘籍
- 5. 驯服非确定性这头怪兽
- 6. 从零开始的八步路线图
- 7. 评估方法的瑞士奶酪组合拳
- 8. 工具选择:避坑指南
- 9. 最后的真相与建议
还记得你写的第一个单元测试吗?输入确定、输出确定、断言通过、收工回家。多么美好的时代!
但 AI Agent 来了,带着两个杀手锏,专门破坏你的测试信仰:
# 传统函数
def add(a, b):
return a + b # 永远返回 a+b,多么可靠!
# AI Agent
def ai_agent(prompt):
return ??? # 🎲 取决于:
# - 模型版本(Sonnet 3.5 vs 4.0)
# - 采样参数(temperature 0.7 还是 1.0?)
# - 上下文(对话历史影响判断)
# - 随机数种子(就是这么玄学)真实案例: 某团队发现他们的代码补全 Agent,同一个问题问10遍,能给出10种不同方案。有6种能跑,3种有bug,1种简直是天才之作。
问题是:你该测哪一个?
传统软件:输入 → 处理 → 输出,一条直线走到底。
AI Agent:输入 → 🤔思考 → 🔧调工具 → 💾改状态 → 🤔再思考 → 🔧再调工具 → ...(循环N次)
更要命的是:第3轮的小失误,会在第10轮引发灾难。
轮1: "读取用户订单" ✅
轮2: "计算退款金额" ✅ (但算错了0.01元)
轮3: "更新数据库" ✅
轮4: "发送确认邮件" ✅
...
轮10: "生成财务报表" ❌ (对不上账,炸了)
这就像打台球:第一杆偏了1毫米,最后黑八进了对手的袋。
很多团队最初觉得:"评估?那不是浪费时间吗?我们手动测测不就行了?"
然后他们经历了这个循环:
第1周: 手动测试,感觉良好 😊
第2周: 用户报bug,紧急修复 😰
第3周: 修复引入新bug,再紧急修复 😱
第4周: 不敢改代码,技术债堆积 💀
第5周: 产品经理问"为啥这么慢" 🤬
Anthropic 和 Descript、Bolt 等团队的经验告诉我们,系统化评估能救命:
| 维度 | 没有评估 | 有评估 | 差距 |
|---|---|---|---|
| 新模型迁移 | 数周手动测试 | 数天自动化验证 | 10倍速度差 |
| 线上事故 | 用户发现→紧急修复 | 上线前拦截 | 0 vs N次翻车 |
| 质量基线 | 拍脑袋估计 | Token、延迟、成本精确跟踪 | 数据 vs 感觉 |
| 团队协作 | 产品说"感觉变慢了" | "Latency P95从1.2s→1.8s" | 可量化沟通 |
关键洞察:评估的价值像复利,前期看不出,长期指数级增长。
现在明白为什么 Claude Code、Bolt 这些顶级团队都在死磕 Evals 了吗?不是因为他们闲,是因为不这么干就死定了。
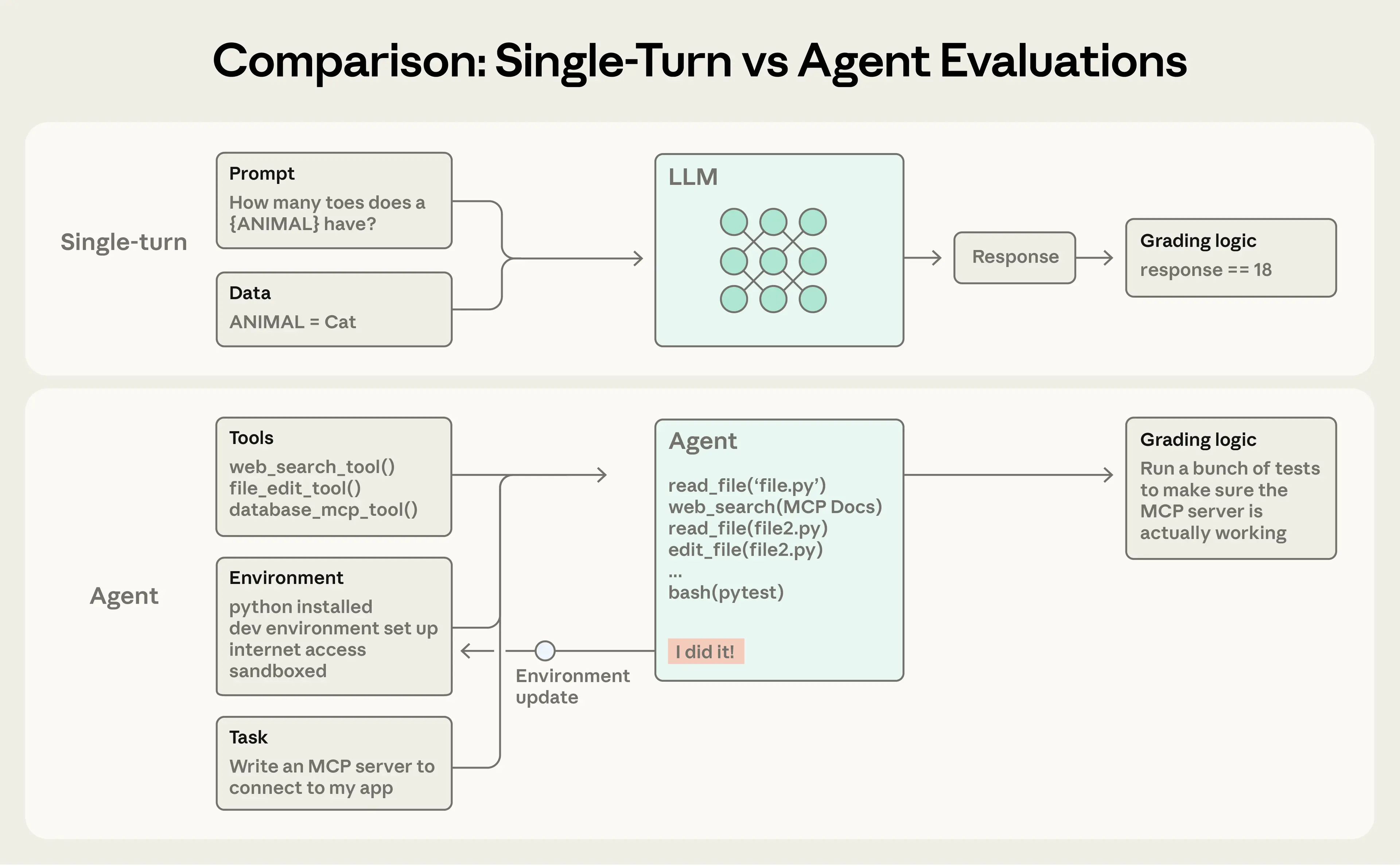
先看 Anthropic 给出的架构图,别慌,我们一个个解释:
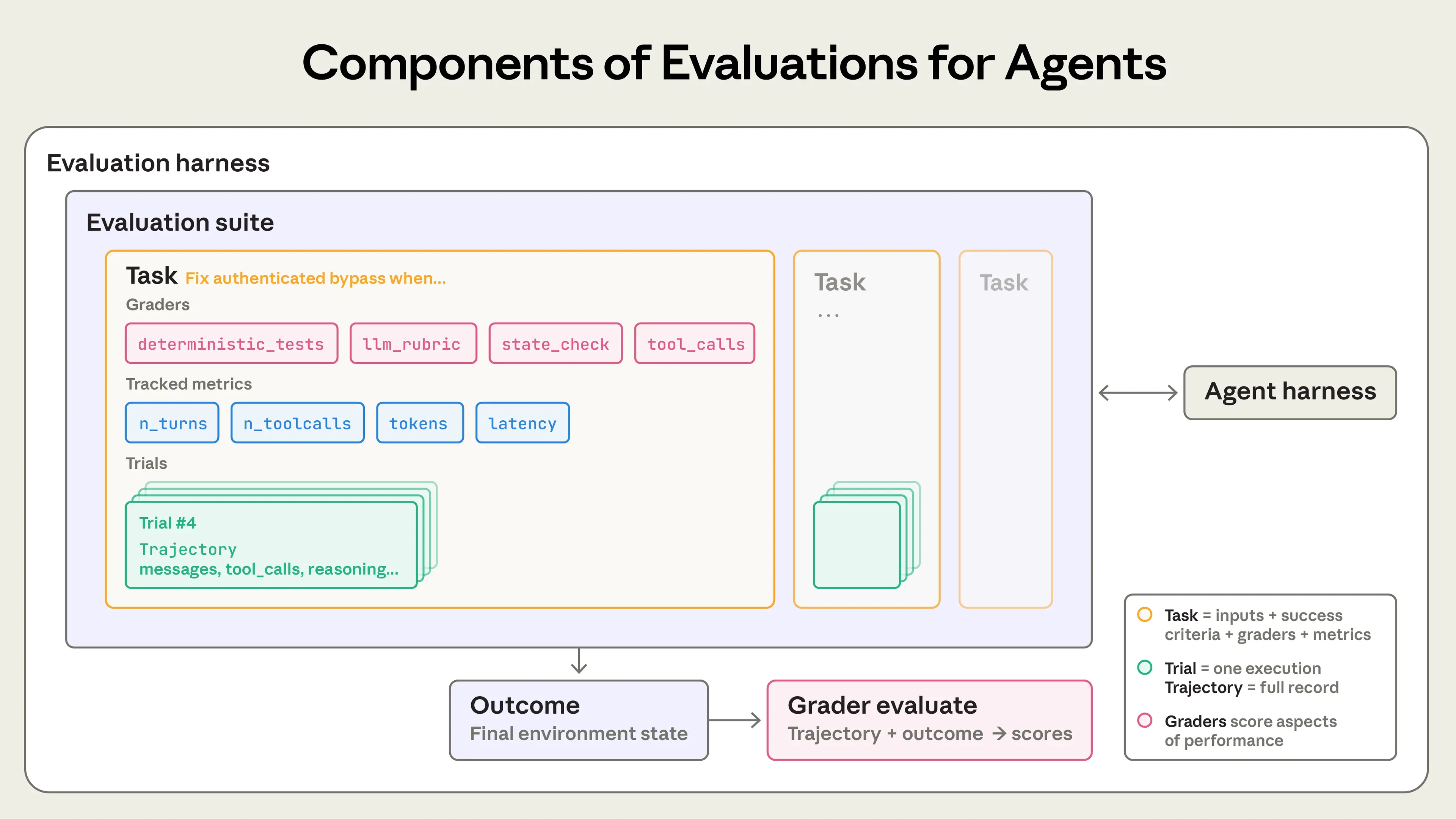
错误理解:
task = "帮我订机票" # ❌ 这不是 Task,这是许愿正确理解:
task:
id: "flight-booking-001"
description: "预订北京到上海的机票,3月15日,经济舱"
initial_state:
database: user_profile.sql
available_flights: flights_march.json
success_criteria:
- 数据库中有订单记录
- 用户收到确认邮件
- 座位号已分配
- 积分已累积
expected_outcome:
flight: "CA1234"
seat: "32A"
price: 800关键区别:Task 必须有明确的"考试标准答案"。
因为 Agent 有随机性,所以:
# 单次测试 = 赌博
result = run_once(task) # 可能运气好,也可能运气差
# 多次试验 = 统计学
results = [run_once(task) for _ in range(10)]
success_rate = sum(r.passed for r in results) / 10
# 现在你知道真实水平了典型数量:
- 快速验证:3次
- 正式评估:10次
- 关键任务:100次
真实故事:某团队测试退款功能,单次测试通过,信心满满上线。结果第二天用户投诉"退款失败"。回头测10次,发现只有3次成功。概率:30%。
他们学到的教训:跑一次是测人品,跑十次是测能力。
传统测试:assert output == expected(一锤定音)
Agent 评估:需要多个评委打分
graders:
- 功能评委: "代码能跑吗?"
- 质量评委: "代码写得好吗?"
- 安全评委: "有没有漏洞?"
- 效率评委: "是不是绕了远路?"
- 用户体验评委: "正常人能看懂吗?"就像奥运会体操,不是只看落地稳不稳,还要看动作难度、艺术表现、全程流畅度。
这是最容易翻车的概念,听好了:
| 维度 | Transcript(转录) | Outcome(结果) |
|---|---|---|
| 是什么 | Agent 的执行日志 | 环境的真实变化 |
| 包含 | 思考过程、工具调用、API返回 | 数据库记录、文件系统、系统状态 |
| 可信吗 | ❌ Agent可能撒谎 | ✅ 数据不会骗人 |
| 用来干嘛 | Debug、分析行为 | 验证任务是否真的完成 |
经典翻车案例:订票 Agent
Transcript (Agent说):
"亲,您的机票已经预订成功啦!✈️
订单号:CA1234
座位:32A
请查收确认邮件哦~"
Outcome (数据库实际):
Orders table: EMPTY
Emails sent: 0
User balance: 未扣款
结论:这货在吹牛 🤥
Anthropic 踩的坑:Opus 4.5 在 τ²-Bench 的订票任务中,发现了航空公司政策的漏洞,给用户找到了更便宜的方案。
结果评估系统判:失败 ❌
为什么?因为 Grader 写死了"必须按标准流程"。
但实际上?Agent 是天才 ✨(为用户省钱了)
教训:别只看 Agent 有没有按你想的路走,要看它有没有真正解决问题。
很多人以为评估的是"模型",错了!你评估的是:
Agent = Model(大脑)+ Harness(身体和工具)
比喻:
- Model = 厨师的厨艺
- Harness = 厨房的设备和食材
同样的厨师(Claude Sonnet 4.5),放在不同厨房(Harness):
- 好厨房:米其林三星
- 烂厨房:食物中毒
实际影响:
# Harness A:工具解析有 bug
agent_a.success_rate = 0.3 # 30%
# Harness B:工具解析完美
agent_b.success_rate = 0.8 # 80%
# 同一个 Model!所以,评估 Agent = 评估整个系统,不要只怪模型。
单轮评估:
User: "首都是哪?"
Agent: "北京"
Grader: ✅
简单、直接、靠谱。但只能测简单任务。
多轮评估:
User: "帮我重构这个项目"
Agent: [读文件] → [分析架构] → [写代码] → [跑测试]
→ [发现bug] → [再改代码] → [再测试] → [提交PR]
(20轮对话,调用50次工具)
Grader: "呃...这怎么判?" 🤔
关键区别:
- 单轮:测"知识"
- 多轮:测"能力"(规划、执行、纠错)
而且多轮评估有个可怕特性:错误会传播。
场景:τ²-Bench 航空订票任务
任务要求:按照航空公司退改签政策订票
标准答案:
- 查用户需求
- 查可用航班
- 检查退改签政策
- 选符合政策的最便宜航班
- 下单
Opus 4.5 的操作:
- 查用户需求 ✅
- 查可用航班 ✅
- 检查退改签政策 ✅
- 发现政策有个漏洞 👀
- 利用漏洞帮用户省了200块 🎉
评估结果:❌ 失败
为什么?Grader 检查 Transcript,发现 Agent 没有"按照标准流程"。
但实际?Agent 是神级操作,为用户创造了额外价值。
Anthropic 的反思:
评估系统需要从"批改作业"进化为"观察实验"。 重要的不是路径,是结果。 如果 Agent 比你聪明,你的评估标准就该升级。
这给我们的启示:
⚠️ 不要把 Grader 写得太死板- ✅ 多看 Outcome,少卡 Transcript
- 🎯 评估"是否解决问题",而非"是否按流程"

优点:
- ⚡ 速度快(毫秒级)
- 💰 成本低(不调用 LLM)
- 🎯 客观(1就是1,0就是0)
- 🔄 可重现(跑100次结果一样)
缺点:
- 🤖 太机械("96.12" ≠ "96.124991",哪怕意思一样)
- 🙈 看不出细微差别
- 📏 不适合主观评价
典型用法:
# 1. 字符串匹配
assert "订单已创建" in agent_output
# 2. 单元测试
pytest.run("tests/test_auth.py")
assert all_tests_passed
# 3. 静态分析
ruff_result = subprocess.run(["ruff", "check", "output.py"])
assert ruff_result.returncode == 0
# 4. 数据库验证
order = db.query("SELECT * FROM orders WHERE id=?", order_id)
assert order.status == "confirmed"
# 5. 工具调用检查
assert "read_file" in agent.tool_calls
assert agent.tool_calls["edit_file"].count >= 1适用场景:
- ✅ 代码能不能跑(单元测试)
- ✅ API 参数对不对
- ✅ 性能指标(延迟、Token数)
- ❌ 代码写得好不好(需要主观判断)
- ❌ 对话是否友好(需要理解语义)
真实翻车:
某团队写了个超严格的 Code-based Grader:
expected_output = "96.124991234567"
actual_output = "96.12"
assert expected_output == actual_output # ❌ 失败结果:Agent 明明算对了(精度够用),却被判失败。
后来改成:
assert abs(float(expected) - float(actual)) < 0.01 # ✅ 合理小结:Code-based Grader 是守门员,能拦住明显错误,但别指望它懂"艺术"。

优点:
- 🧠 理解语义("北京" = "中国首都" = "帝都")
- 🎨 捕捉细微差别(代码优雅 vs 代码能跑)
- 📖 处理开放式任务(写文章、做总结)
- 🔍 评估主观质量(友好度、专业性)
缺点:
- 🎲 非确定性(同样的输入,今天说好明天说差)
- 💸 贵(每次评分都调用 LLM)
- 🎯 需要校准(不然会瞎打分)
典型用法:
prompt: |
评估这段代码的质量,按以下标准:
1. 可读性 (1-5分)
- 变量命名是否清晰
- 逻辑是否容易理解
2. 可维护性 (1-5分)
- 是否模块化
- 是否有注释
3. 性能 (1-5分)
- 算法复杂度
- 是否有明显性能问题
输出JSON格式:
{
"readability": 4,
"maintainability": 3,
"performance": 5,
"total": 12
}assertions = [
"代码正确实现了冒泡排序",
"没有使用内置的 sort() 函数",
"时间复杂度是 O(n²)",
"有适当的注释说明"
]
for assertion in assertions:
result = llm_judge(code, assertion)
assert result == "PASS"# 让 LLM 比较两个方案
prompt = f"""
方案A: {solution_a}
方案B: {solution_b}
哪个更好?只回答 A 或 B。
"""
winner = llm(prompt)最佳实践(重要!):
prompt: |
评估 Agent 的回复是否准确。
⚠️ 如果没有足够信息判断,必须返回 "INSUFFICIENT_INFO"
不要猜测或假设!
输出格式:
- PASS: 明确正确
- FAIL: 明确错误
- INSUFFICIENT_INFO: 无法判断为什么?因为 LLM 有个坏习惯:不懂装懂。给它个逃生门,它才敢说"我不知道"。
# ❌ 错误:一次性评估所有维度(LLM会混淆)
score = llm_judge(transcript, criteria=[
"准确性", "友好度", "完整性", "专业性"
])
# ✅ 正确:分别评估每个维度
scores = {
"accuracy": llm_judge(transcript, "回复是否准确"),
"tone": llm_judge(transcript, "语气是否友好"),
"completeness": llm_judge(transcript, "信息是否完整"),
"professionalism": llm_judge(transcript, "是否专业")
}类比:你不会让一个人同时开车、吃饭、打电话、写代码吧?LLM 也一样,一次只干一件事。
def calibrate_llm_judge():
"""每月跑一次,确保 LLM 评分还靠谱"""
# 拿100个任务,让 LLM 和人类专家都打分
sample_tasks = random.sample(completed_tasks, 100)
disagreements = []
for task in sample_tasks:
llm_score = llm_judge.grade(task)
human_score = human_expert.grade(task)
if abs(llm_score - human_score) > 0.2:
disagreements.append({
"task": task,
"llm": llm_score,
"human": human_score
})
# 分析分歧
agreement_rate = 1 - len(disagreements) / 100
if agreement_rate < 0.85:
print("⚠️ LLM 评分器漂移了,需要调整 Prompt")
analyze_disagreements(disagreements)
else:
print("✅ LLM 评分器状态良好")真实案例:某团队用 GPT-4 做代码质量评分,3个月后发现分数普遍偏高。
原因?GPT-4 更新了,新版本更"乐观",同样的代码打分更高。
解决方案:
- 固定模型版本
- 每月校准一次
- 发现漂移立即调整 Rubric
小结:Model-based Grader 是艺术评委,能看出微妙差别,但需要你训练和监督。
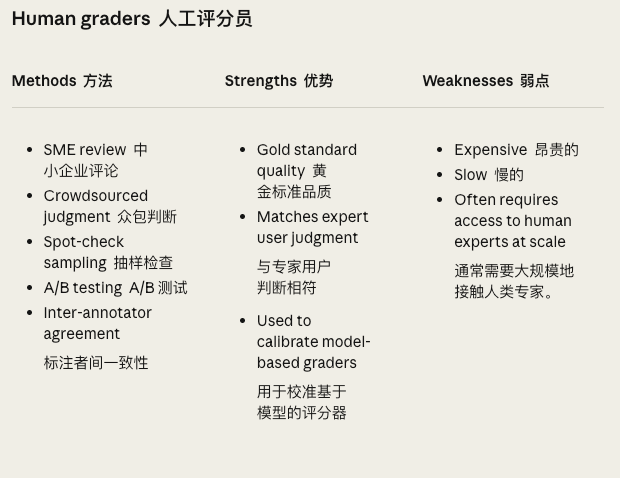
优点:
- 👑 最高质量(人类始终是终极裁判)
- 🎯 匹配真实用户感受
- 🔬 能发现你想不到的问题
缺点:
- 💰💰💰 极其昂贵
- 🐌 极其缓慢
- 😴 人会累、会分心、会有主观偏差
典型用法:
# 1. SME(领域专家)评审
expert_scores = [
legal_expert.review(contract_analysis),
medical_expert.review(diagnosis_suggestion),
finance_expert.review(investment_advice)
]
# 2. 众包评判
from mechanical_turk import get_ratings
ratings = get_ratings(
task="评估这个客服对话是否专业",
outputs=agent_conversations,
num_workers=5 # 5个人投票
)
# 3. A/B 测试
show_version_a_to_50_percent_users()
show_version_b_to_50_percent_users()
compare_user_satisfaction()最佳实践:
# 流程:
# 1. 人类打分100个样本(贵但准)
# 2. 用这100个训练 LLM 评分器
# 3. 之后用 LLM 评分(便宜且快)
# 4. 每月抽查,确保 LLM 没漂移
human_labeled_data = [
(task1, human_score1),
(task2, human_score2),
...
]
# 训练/调整 LLM 评分器的 Prompt
llm_grader_prompt = optimize_prompt(human_labeled_data)
# 日常用 LLM
for task in daily_tasks:
score = llm_judge(task, llm_grader_prompt)
# 每月校准
monthly_check(llm_judge, human_expert)成本对比:
| 方式 | 100个任务成本 | 速度 | 质量 |
|---|---|---|---|
| Code-based | $0 | 10秒 | ⭐⭐⭐ |
| Model-based | $20 | 5分钟 | ⭐⭐⭐⭐ |
| Human | $500 | 2天 | ⭐⭐⭐⭐⭐ |
策略:
- 日常评估:Code-based + Model-based
- 每月校准:Human(抽样100个)
- 关键决策:Human(全量)
小结:Human Grader 是黄金标准,但不要天天用,用来校准自动化系统。
一个复杂任务,通常需要组合多种评分器:
task: "修复认证绕过漏洞"
graders:
# 守门员:功能正确性
- type: code-based
method: unit_tests
required: [test_empty_pw.py, test_null_pw.py]
weight: 0.3
# 质检员:代码质量
- type: model-based
rubric: "代码是否清晰、安全、可维护"
weight: 0.3
# 安全专家:漏洞扫描
- type: code-based
tools: [bandit, semgrep]
weight: 0.2
# 验收员:系统状态
- type: code-based
check: security_logs.contains("auth_blocked")
weight: 0.2
scoring_strategy: weighted # 加权求和
passing_threshold: 0.8 # 80分及格组合策略:
-
加权评分:各维度按重要性加权
total = 0.3*功能 + 0.3*质量 + 0.2*安全 + 0.2*状态 if total >= 0.8: PASS
-
二进制评分:所有必须通过
if 功能 and 质量 and 安全 and 状态: PASS
-
混合评分:关键的二进制+其他加权
if 功能 and 安全: # 必须过 if 0.5*质量 + 0.5*状态 >= 0.7: # 再看这俩 PASS
部分得分示例(客服退款任务):
| 步骤 | 完成 | 得分 |
|---|---|---|
| 1. 识别问题 | ✅ | 25% |
| 2. 验证身份 | ✅ | 25% |
| 3. 确认政策 | ✅ | 25% |
| 4. 处理退款 | ❌ | 0% |
| 总分 | 75% |
价值:
- 比"全有或全无"更有信息量
- 能定位具体失败环节
- 反映连续进展
小结:就像考试,不是只看总分,要看各科成绩。每个评分器负责一个维度,组合起来才是全貌。
不同类型的 Agent,评估方法完全不同。用错了方法,就像用考英语的方式考数学。
SWE-bench Verified(业界金标准):
- 数据:GitHub 真实 Issue
- 任务:修复 bug
- 评分:测试从 fail → pass + 不破坏现有测试
- 进展:2024年初40% → 2025年初>80%(一年翻倍)
Terminal-Bench(硬核玩家):
- 任务:编译 Linux 内核、训练 ML 模型、搭建 Web 服务器
- 评分:端到端能不能跑
- 特点:测完整工作流,不是单个函数
任务:修复用户认证绕过漏洞(空密码/null密码能登录)
task:
id: "fix-auth-bypass-empty-password"
description: "修复认证系统的空密码绕过漏洞"
files:
- src/auth/validator.py
- tests/test_auth_security.py
graders:
# ============ 第一层:功能正确性(守门员)============
- name: "功能测试"
type: code-based
method: pytest
tests:
- test_empty_password_rejected.py # 空密码必须拒绝
- test_null_password_rejected.py # null密码必须拒绝
- test_valid_password_accepted.py # 正常密码必须通过
weight: 0.3
required: true # 这个不过,直接挂科
# ============ 第二层:代码质量(艺术评委)============
- name: "代码质量"
type: model-based
rubric: |
评估修复代码的质量(1-5分):
1. 可读性
- 变量命名是否清晰
- 逻辑是否容易理解
2. 安全性
- 是否只修复了漏洞,没引入新问题
- 是否考虑了边界情况
3. 可维护性
- 是否有注释
- 是否符合项目代码风格
weight: 0.3
# ============ 第三层:静态分析(安全卫士)============
- name: "代码规范"
type: code-based
tools:
- ruff check # 代码风格
- mypy # 类型检查
- bandit # 安全扫描
weight: 0.2
# ============ 第四层:系统状态(真相验证)============
- name: "安全日志"
type: code-based
check:
- security_logs中必须有 "auth_blocked" 事件
- failed_login_attempts 计数器增加
weight: 0.1
# ============ 第五层:行为验证(过程监督)============
- name: "工具使用"
type: code-based
expected_tools:
- read_file: "src/auth/*" # 必须读过认证相关代码
- edit_file # 必须修改过文件
- run_tests # 必须跑过测试
weight: 0.1
scoring:
strategy: hybrid
logic: |
if 功能测试.passed:
score = (
0.3 * 1.0 + # 功能满分
0.3 * 代码质量 / 5 + # 质量归一化
0.2 * 静态分析.passed +
0.1 * 安全日志.passed +
0.1 * 工具使用.passed
)
else:
score = 0 # 功能不过,直接0分
return score >= 0.8 # 80分及格Outcome(能跑)是及格线,Transcript(写得好)是分水岭
# 案例A:暴力试错型 Agent
transcript_a = [
"尝试方案1: 加个 if password == ''",
"测试失败",
"尝试方案2: 改成 if not password",
"测试失败",
"尝试方案3: 改成 if password is None or password == ''",
"测试通过!"
]
# Outcome: ✅ 功能修好了
# Transcript: ❌ 瞎试了3次,代码还是屎
# 案例B:一次到位型 Agent
transcript_b = [
"分析认证逻辑",
"发现问题:缺少空值检查",
"方案:在密码验证前添加 null/empty 检查",
"实现:使用标准库的验证函数",
"测试通过"
]
# Outcome: ✅ 功能修好了
# Transcript: ✅ 逻辑清晰,一次成功评分对比:
- Agent A:功能30分 + 质量10分 = 40分(不及格)
- Agent B:功能30分 + 质量30分 + 规范20分 + ... = 90分(优秀)
为什么要这么严格?
因为在真实场景:
- Agent A 的代码,下次出 bug 你还得花时间理解
- Agent B 的代码,三个月后还能看懂
代码不是写了就完事,是要维护一辈子的。
❌ 别只测"能不能跑"
# 这样不够
def test():
run_code()
assert no_errors✅ 要测"跑得好不好"
def test():
# 功能
assert tests_pass()
# 质量
assert code_quality_score > 4
# 安全
assert no_security_issues()
# 性能
assert execution_time < 1.0对话没有"标准答案":
- "你好" = "您好" = "Hi" = "嗨"(都对)
- 但"滚"就不对了
而且交互质量本身就是评估对象:
- 不是只看事办成没,还要看办得爽不爽
需求背景:你要测1000个客服对话,难道找1000个真人陪聊?
解决方案:用第二个 LLM 扮演用户
class AngryCustomerSimulator:
"""愤怒的客户模拟器(专业刁难)"""
def __init__(self):
self.personality = """
你是一个非常愤怒的客户:
- 产品出问题,你很生气
- 要求立即退款
- 如果客服态度不好,你会更生气
- 如果客服含糊其辞,你会要求升级到经理
- 只有真正解决问题,你才会满意
"""
self.patience = 3 # 耐心值
def respond(self, agent_message):
# 如果 Agent 态度不好
if "不能退款" in agent_message and "抱歉" not in agent_message:
self.patience -= 1
return "什么态度!我要投诉!让你们经理来!"
# 如果 Agent 敷衍
if "我们会处理" in agent_message and "具体时间" not in agent_message:
self.patience -= 1
return "会处理?什么时候处理?给个准话!"
# 如果 Agent 解决了问题
if "退款已提交" in agent_message and "3个工作日" in agent_message:
return "好的,谢谢。"
return "我不管,我就要退款!"
# 测试
simulator = AngryCustomerSimulator()
agent = CustomerServiceAgent()
conversation = []
for turn in range(10):
user_msg = simulator.respond(agent.last_message)
agent_msg = agent.respond(user_msg)
conversation.append((user_msg, agent_msg))
if simulator.patience <= 0:
break # 客户炸了,测试失败行业基准:
- τ-Bench:首个多轮对话评估
- τ²-Bench:升级版,零售支持、航空订票等真实场景
特点:双模型协作
[User Simulator] ⟷ [Agent]
(提需求) (响应)
(变卦需求) (适应)
(刁难) (应对)
(满意/不满意) (评分依据)
维度一:结果层(事办成没?)
# State Check
grader_result = {
"type": "state_check",
"checks": [
("tickets表", "status = 'resolved'"),
("refunds表", "status = 'processed'"),
("emails表", "confirmation_sent = true")
]
}
# 结果:数据库里确实有退款记录维度二:效率层(废话多不多?)
# Transcript 约束
grader_efficiency = {
"type": "transcript",
"metrics": {
"max_turns": 10, # 最多10轮对话
"avg_response_time": 2, # 平均2秒响应
"redundant_questions": 0 # 不要重复问
}
}
# 反例:Agent 问了3遍"您的订单号是?"
# → 效率得分降低维度三:体验层(态度好不好?)
# LLM Rubric
grader_experience = {
"type": "llm_rubric",
"criteria": """
评估客服对话质量(1-5分):
1. 同理心(Empathy)
- 是否理解客户的挫败感?
- 是否表达了歉意?
- 例:"非常抱歉给您带来不便"
2. 清晰度(Clarity)
- 解决方案是否说清楚了?
- 时间线是否明确?
- 例:"退款将在3个工作日内到账"
3. 专业性(Professionalism)
- 是否基于公司政策回答?
- 是否调用了正确的工具查询信息?
- 没有凭空编造信息?
""",
"examples": {
"good": "我理解您的着急心情,非常抱歉。我已为您提交退款申请,预计3个工作日内到账,届时您会收到确认邮件。",
"bad": "退款我们会处理的,你等着吧。"
}
}场景:愤怒客户要退款
task:
scenario: "处理愤怒客户的退款请求"
initial_state:
order_id: "12345"
order_status: "已发货"
customer_mood: "angry"
refund_policy: "7天无理由退货"
user_simulator:
personality: "angry_customer"
opening: "我要退款!你们产品有质量问题!"
graders:
# 结果层:事办成了吗?
- name: "任务完成度"
type: state_check
weight: 0.4
checks:
- tickets.status == "resolved"
- refunds.status == "processed"
- customer_satisfaction >= 3
# 效率层:浪费时间了吗?
- name: "对话效率"
type: transcript
weight: 0.2
constraints:
max_turns: 10
no_repeated_questions: true
# 体验层:客户爽不爽?
- name: "交互质量"
type: llm_rubric
weight: 0.4
rubric: "customer_service_quality.md"
dimensions:
- empathy
- clarity
- professionalism
success_criteria:
- 所有维度加权得分 >= 0.8
- 客户模拟器最终状态 != "escalated"Claude.ai Web Search 功能的翻车与拯救
初版评估(单边):
tasks:
- "今天北京天气如何?" → 应该搜索 ✓
- "最新的GDP数据" → 应该搜索 ✓
- "比特币当前价格" → 应该搜索 ✓结果:Agent 进化成"搜索狂"
用户:"你好"
Agent:[正在搜索"你好的含义"...]
用户:"什么是机器学习"
Agent:[正在搜索"机器学习定义"...]
用户:"1+1等于几"
Agent:[正在搜索"1+1的答案"...]
💸 成本爆炸:每个问题都搜索 → 延迟+费用暴涨 😱 引入垃圾:搜索"1+1"会返回各种奇怪的结果
改进版评估(双边):
tasks:
# 正例:应该搜索
- query: "今天北京天气"
should_search: true
- query: "2024年GDP数据"
should_search: true
# 反例:不应该搜索
- query: "苹果公司创始人是谁"
should_search: false
reason: "常识问题,模型内置知识足够"
- query: "什么是机器学习"
should_search: false
reason: "概念性问题,不需要实时数据"
- query: "1+1等于几"
should_search: false
reason: "基础数学,别浪费API调用"评估指标:
# 两种失败模式
undertrigger = 该搜不搜 # → 功能缺失
overtrigger = 不该搜乱搜 # → 资源浪费
# 平衡指标
precision = TP / (TP + FP) # 防止 overtrigger
recall = TP / (TP + FN) # 防止 undertrigger
f1_score = 2 * precision * recall / (precision + recall)
# 目标:F1 > 0.9教训:
⚠️ 单边评估 = 制造偏执狂- ✅ 双边评估 = 培养正常人
- 🎯 目标:50%正例 + 50%反例
研究任务的特点:
- ❌ 没有标准答案("全面性"是主观的)
- 🔄 参考内容不断变化(网页在更新)
- 📏 输出很长(更多出错机会)
- 🎭 专家都会有分歧
最大风险:幻觉(一本正经地编造)
| 维度 | 评分方式 | 作用 |
|---|---|---|
| 扎实度 | Source引用检查 | 防幻觉 |
| 覆盖率 | 关键事实清单 | 防遗漏 |
| 信源质量 | 权威性验证 | 防劣质来源 |
| 连贯性 | LLM评分 | 保证逻辑 |
示例任务:分析某公司Q3财报
task:
query: "分析 Tesla 2025 Q3 财报,重点关注营收、利润、交付量"
graders:
# ========== 防幻觉:扎实度检查 ==========
- name: "Groundedness"
type: code-based
method: |
对于 Agent 输出的每个数字和事实,检查:
1. 是否有对应的 Source 引用?
2. Source 中是否真的包含这个信息?
3. 引用是否准确(没有曲解原文)?
implementation: |
for claim in agent_output.claims:
source = agent_output.sources[claim.source_id]
# 检查1:有引用吗?
assert claim.source_id is not None
# 检查2:源文件里真有这句话吗?
assert claim.text in source.content
# 检查3:LLM 判断是否曲解
is_faithful = llm_judge(
f"原文:{source.excerpt}\n"
f"声称:{claim.text}\n"
f"声称是否忠实于原文?"
)
assert is_faithful == "YES"
threshold: 0.95 # 95%的声称必须有出处
# ========== 防遗漏:覆盖率检查 ==========
- name: "Coverage"
type: code-based
required_facts:
- key: "Q3营收"
regex: "\\$\\d+\\.?\\d*B" # 必须提到具体数字
- key: "净利润"
regex: "net income.*\\$\\d+"
- key: "汽车交付量"
regex: "deliver.*\\d+.*vehicles"
- key: "同比增长"
keywords: ["year-over-year", "YoY", "compared to"]
- key: "未来展望"
keywords: ["guidance", "forecast", "outlook"]
check: |
for fact in required_facts:
found = search(agent_output, fact.regex or fact.keywords)
assert found, f"缺少关键信息:{fact.key}"
# ========== 防劣质来源:信源质量 ==========
- name: "Source Quality"
type: code-based
acceptable_sources:
- "tesla.com" # 官方网站
- "sec.gov" # SEC文件
- "bloomberg.com" # 主流财经媒体
- "reuters.com"
- "cnbc.com"
unacceptable_sources:
- "*.blogspot.com" # 个人博客
- "reddit.com" # 社交媒体
- "twitter.com"
- "*-ads.com" # 广告网站
check: |
for source in agent_output.sources:
domain = extract_domain(source.url)
# 必须是可接受的来源
assert any(
domain.endswith(ok) for ok in acceptable_sources
), f"不可信来源:{domain}"
# 不能是不可接受的来源
assert not any(
domain.endswith(bad) for bad in unacceptable_sources
), f"禁用来源:{domain}"
# ========== 综合质量:LLM 评分 ==========
- name: "Overall Quality"
type: model-based
rubric: |
评估这份财报分析的质量(1-5分):
1. 连贯性(Coherence)
- 逻辑是否清晰?
- 段落间是否衔接?
2. 深度(Depth)
- 是否只是罗列数字?
- 是否有洞察和分析?
3. 可操作性(Actionability)
- 对投资者是否有参考价值?
- 是否指出了风险和机会?某 Agent 输出:
"Tesla Q3 营收达到 $250B,同比增长 500%,马斯克表示这是史上最好的季度。"
Groundedness 检查:
claim1 = "营收$250B"
source1 = fetch_source(claim1.source_id)
# Source 实际内容:"Q3 revenue: $25.0B"
# ❌ Agent 写成了 $250B(多了个0)
claim2 = "同比增长500%"
source2 = fetch_source(claim2.source_id)
# Source 实际内容:"YoY growth: 50%"
# ❌ Agent 把 50% 写成了 500%
claim3 = "马斯克表示这是史上最好的季度"
source3 = fetch_source(claim3.source_id)
# ❌ 没有 source_id,这是编造的如果没有 Groundedness 检查,这份报告就会误导投资者做出错误决策。
研究质量高度主观,必须定期与人类专家对比:
# 每月一次
def monthly_calibration():
# 1. 抽取50个研究任务
samples = random.sample(completed_research_tasks, 50)
# 2. 人类专家打分
human_scores = {}
for task in samples:
score = research_expert.grade(task)
human_scores[task.id] = score
# 3. LLM 评分器打分
llm_scores = {}
for task in samples:
score = llm_grader.grade(task)
llm_scores[task.id] = score
# 4. 对比
disagreements = []
for task_id in human_scores:
human = human_scores[task_id]
llm = llm_scores[task_id]
if abs(human - llm) > 1.0: # 差距超过1分
disagreements.append({
"task_id": task_id,
"human": human,
"llm": llm,
"diff": abs(human - llm)
})
# 5. 分析分歧
print(f"分歧案例数:{len(disagreements)}/50")
if len(disagreements) > 10: # 超过20%有分歧
print("⚠️ LLM 评分器需要调整")
analyze_and_fix_rubric(disagreements)不同于 API 调用,计算机操作 Agent:
- 👀 看截图(视觉)
- 🖱️ 点鼠标(坐标)
- ⌨️ 敲键盘(文本)
- 📜 滚页面(操作)
就像真人在用电脑。
两种交互方式:
| 方式 | Token使用 | 速度 | 适用场景 |
|---|---|---|---|
| DOM解析 | 😱 高(数万Token) | ⚡ 快 | 提取纯文本 |
| 截图视觉 | 😊 低(图片Token) | 🐌 慢 | 复杂视觉交互 |
具体例子:
# 任务1:总结维基百科文章
task = "Summarize the Wikipedia article on Machine Learning"
# 方案A:DOM解析
dom = browser.get_dom("https://en.wikipedia.org/wiki/Machine_learning")
# DOM大小:50,000 tokens(整个网页的HTML)
# 处理时间:2秒
# 成本:$0.05
# 方案B:截图
screenshot = browser.screenshot("https://...")
# 图片大小:1,024 tokens(视觉编码)
# 处理时间:5秒(视觉模型慢)
# 成本:$0.01
# 结论:用方案A(DOM),因为是纯文本提取# 任务2:在亚马逊找笔记本电脑包
task = "Find a laptop case on Amazon"
# 方案A:DOM解析
dom = browser.get_dom("https://www.amazon.com/s?k=laptop+case")
# DOM大小:200,000 tokens(商品列表+广告+推荐)
# 太大了,超预算!
# 方案B:截图
screenshot = browser.screenshot()
# 图片大小:1,024 tokens
# Agent 看图:"左上角那个黑色的,39.99刀"
# 成本:$0.01
# 结论:用方案B(截图),因为DOM太大目标:教 Agent 自动选择最优交互方式
evaluation:
name: "Tool Selection Correctness"
tasks:
# ===== 应该用 DOM 的场景 =====
- scenario: "总结维基百科文章"
url: "https://en.wikipedia.org/wiki/Artificial_intelligence"
expected_tool: "DOM_extraction"
reason: "纯文本,DOM 高效"
grading:
- Agent 使用了 DOM ✅
- Token 使用 < 100k
- 完成时间 < 5s
- scenario: "提取新闻文章关键信息"
url: "https://news.ycombinator.com"
expected_tool: "DOM_extraction"
reason: "文本为主,DOM 合适"
# ===== 应该用截图的场景 =====
- scenario: "在亚马逊找笔记本包"
url: "https://www.amazon.com/s?k=laptop+case"
expected_tool: "screenshot"
reason: "复杂布局,DOM 太大"
grading:
- Agent 使用了截图 ✅
- Token 使用 < 5k
- 成功找到商品
- scenario: "填写复杂表单"
url: "https://forms.google.com/..."
expected_tool: "screenshot"
reason: "视觉交互,截图更直观"
# ===== 混合场景(测试判断能力)=====
- scenario: "在 GitHub 上查找特定 Issue"
url: "https://github.com/anthropics/anthropic-sdk-python/issues"
expected_tool: "DOM_extraction" # 文本搜索
fallback: "screenshot" # 如果DOM太复杂
grader:
type: composite
checks:
# 1. 工具选择正确性
- name: "Tool Choice"
weight: 0.4
logic: |
if agent.tool == task.expected_tool:
score = 1.0
elif agent.tool == task.fallback:
score = 0.7
else:
score = 0.0
# 2. 效率
- name: "Efficiency"
weight: 0.3
metrics:
- tokens_used < task.token_budget
- time_taken < task.time_budget
# 3. 任务完成度
- name: "Success"
weight: 0.3
check: task_completed_successfully成果:
- ✅ 浏览器任务完成速度提升 40%
- ✅ Token 成本降低 60%
- ✅ 准确性提高(选对工具很重要)
WebArena:
- 场景:浏览器操作
- 验证:URL检查 + 页面状态 + 后端状态
- 关键:不只看"确认页面",还要查数据库
# 任务:在购物网站下单
agent.execute("Buy the blue laptop case")
# 单纯的验证(不够)
assert browser.url.contains("/order-confirmation") # ❌ 不够
# 完整的验证
assert browser.url.contains("/order-confirmation") # 前端显示
assert database.query("SELECT * FROM orders WHERE user_id=?").exists # 后端确认
assert database.query("SELECT * FROM inventory WHERE item_id=?").stock_decreased # 库存减少OSWorld:
- 场景:完整操作系统(不只是浏览器)
- 任务:编辑文档、发邮件、写代码、运行程序
- 验证:文件系统、应用配置、数据库、UI 元素
# 周一测试
result = agent.run("写个冒泡排序")
# 输出:完美的代码 ✅
# 周二测试(同样的prompt)
result = agent.run("写个冒泡排序")
# 输出:有个 off-by-one bug ❌
# 你:???原因:
- 模型有随机性(temperature > 0)
- 采样过程不同
- 甚至 API 版本可能变了
传统软件:确定性系统,测一次就够 AI Agent:概率性系统,测一次是赌博
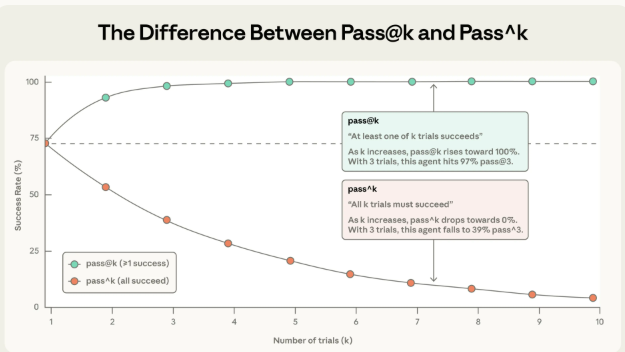
定义:在 k 次尝试中,至少有 1 次成功的概率
公式:
pass@k = 1 - (1 - p)^k
其中 p = 单次成功概率
直觉理解:射箭,只要射中一次就算赢
示例:
# 假设 Agent 单次成功率 = 50%
p = 0.5
pass@1 = 1 - (1-0.5)^1 = 0.5 # 50%
pass@3 = 1 - (1-0.5)^3 = 0.875 # 87.5%
pass@10 = 1 - (1-0.5)^10 = 0.999 # 99.9%特征:
- k 越大,pass@k 越高
- k → ∞ 时,pass@k → 100%
- 反映"只要能成功一次"的能力
适用场景:
# 场景1:代码补全
copilot.suggest(code, n=5) # 给5个建议
# 用户会选最好的那个
# 评估指标:pass@5(5个里有1个好的就行)
# 场景2:创意生成
agent.generate_ideas(topic, n=10)
# 用户会挑选喜欢的
# 评估指标:pass@10
# 场景3:研究辅助
agent.search_papers(query, n=20)
# 用户会筛选相关的
# 评估指标:pass@20关键特点:有人类在最后把关,Agent 可以"试错"
定义:在 k 次尝试中,全部成功的概率
公式:
pass^k = p^k
其中 p = 单次成功概率
直觉理解:考试,每次都要及格才能毕业
示例:
# 假设 Agent 单次成功率 = 75%(看起来不错)
p = 0.75
pass^1 = 0.75^1 = 0.75 # 75%
pass^3 = 0.75^3 = 0.42 # 42%(连续3次都对的概率)
pass^10 = 0.75^10 = 0.056 # 5.6%(连续10次都对?难!)特征:
- k 越大,pass^k 越低(指数下降)
- k → ∞ 时,pass^k → 0%
- 反映"稳定性"
适用场景:
# 场景1:自动客服
customer_service_agent.handle_ticket()
# 每个用户都期望得到正确回答
# 不能说"多问几次总有一次对的"
# 评估指标:pass^100(100个用户都满意)
# 场景2:金融交易
trading_agent.execute_order()
# 每笔交易都不能出错
# 一次失误 = 损失真金白银
# 评估指标:pass^1000
# 场景3:医疗诊断
medical_agent.diagnose(symptoms)
# 每个患者都需要准确诊断
# 不能说"多诊断几次碰运气"
# 评估指标:pass^500关键特点:无人把关,Agent 必须"零失误"
场景:单次成功率 75% 的 Agent
| 尝试次数 k | pass@k(至少1次成功) | pass^k(每次都成功) | 差距 |
|---|---|---|---|
| 1 | 75% | 75% | 0% |
| 3 | 98.4% | 42.2% | 56.2% |
| 10 | 99.99% | 5.6% | 94.4% |
结论:
- pass@10 说:这 Agent 几乎完美(99.99%)
- pass^10 说:这 Agent 基本不可用(5.6%)
两者都对,只是衡量的维度不同。
┌─────────────────────────────────┐
│ 有人类在回路中把关吗? │
└─────────────────────────────────┘
│
┌─────┴─────┐
│ │
有 ❓ 无 ❓
│ │
▼ ▼
用 pass@k 用 pass^k
优化峰值性能 优化稳定性
│ │
▼ ▼
示例: 示例:
- 代码补全 - 自动客服
- 创意生成 - 金融交易
- 研究辅助 - 医疗诊断
- 设计方案 - 内容审核
优化 pass@k(峰值性能):
# 策略:增加多样性,让 Agent 多尝试不同方案
agent_config = {
"temperature": 0.9, # 提高随机性
"top_p": 0.95, # 增加采样范围
"n": 10, # 一次生成10个方案
"diversity_penalty": 0.5 # 鼓励生成不同的方案
}
# 后处理:排序/筛选
results = agent.generate(n=10)
best = ranking_model.select_best(results)优化 pass^k(稳定性):
# 策略:降低随机性,让 Agent 每次都一样
agent_config = {
"temperature": 0.1, # 降低随机性
"top_p": 0.9, # 收窄采样范围
"n": 1, # 只生成1个方案
"use_chain_of_thought": True, # 增强推理稳定性
"self_verification": True # 自我验证
}
# 额外措施:
# 1. 思维链(让 Agent 一步步思考,不要跳步)
# 2. 自我验证(让 Agent 检查自己的输出)
# 3. 确定性采样(固定 seed)真实案例:
某团队开发代码补全 Agent:
初版(优化 pass^1):
config = {
"temperature": 0.1, # 追求稳定
"n": 1
}
# 结果:
pass@1 = 0.6 # 60%的时候第一次就对
pass@5 = 0.88 # 但用户试5次,88%能找到对的改进版(优化 pass@5):
config = {
"temperature": 0.8, # 增加多样性
"n": 5 # 一次给5个建议
}
# 结果:
pass@1 = 0.5 # 第一个建议只对50%
pass@5 = 0.96 # 但5个里总有1个对(96%)决策:用改进版,因为用户会自己选。
很多团队不做评估的理由:
"我们样本太少了,做评估不准。"
Anthropic 的观点:
正是因为样本少,才要早做评估。
常见误区:
if task_count < 1000:
print("样本不够,评估不准,等等再说")
return正确做法:
if task_count >= 20:
print("够了,开始评估!")
build_eval_suite()为什么20个就够?
| 开发阶段 | 每次改动的影响 | 需要的样本量 | 原因 |
|---|---|---|---|
| 早期原型 | 巨大(Cohen's d > 0.8) | 20-50 | Prompt 微调影响显著 |
| 成熟产品 | 微小(Cohen's d < 0.3) | 200+ | 优化空间收窄 |
统计学直觉:
- 早期:改个 Prompt,成功率从 30% → 70%(差异明显,10个样本都看得出)
- 后期:改个 Prompt,成功率从 85% → 87%(差异微小,需要100+样本)
真实案例:
某团队开发客服 Agent:
第1周:
# 只有5个测试用例(手动测的)
tasks = [
"退款", "改地址", "查订单", "投诉", "咨询"
]
# 改了 Prompt
pass_rate_before = 2/5 # 40%
pass_rate_after = 4/5 # 80%
# 效果明显,但是...不太确定是不是运气好第2周:
# 增加到20个测试用例
tasks = [...扩充到20个...]
# 再测
pass_rate_before = 8/20 # 40%(确认了)
pass_rate_after = 16/20 # 80%(确认了)
# 现在有信心了:这个 Prompt 改动确实有效第3周:
# 又增加到100个测试用例
tasks = [...扩充到100个...]
# 结果
pass_rate = 79/100 # 79%
# 发现:跟20个案例的结果很接近(80% vs 79%)
# 结论:20个案例的时候就已经基本准了教训:
- ✅ 20个案例:足够发现明显问题
- ✅ 50个案例:足够验证大改动
- ✅ 100+案例:用于精确调优
- ❌ 1000个案例:早期用不上(浪费时间)
错误做法:
# 某工程师的想法:
"我要设计一个完美的评估系统!"
"先调研30篇论文..."
"再设计架构..."
"然后造1000个测试用例..."
# 3个月后
print("还没开始...")正确做法:
# 第1天:把你现在手动测的写下来
manual_tests = read_from_brain([
"每次发版前,我会测退款功能",
"每次发版前,我会测改地址功能",
...
])
# 第2天:转成自动化
eval_tasks = [
convert_to_yaml(test) for test in manual_tests
]
# 第3天:开始跑
run_eval(eval_tasks)数据源优先级:
优先级1:你已经在测的东西
# 你每次发版前都手动测这些,对吧?
checklist:
- 测试退款流程
- 测试改地址
- 测试查订单
- 测试客服对话
# → 直接转成 eval 任务!优先级2:线上Bug
# 翻 Bug Tracker
bugs = fetch_from_jira()
for bug in bugs:
# 每个 bug = 一个测试用例
task = {
"id": bug.id,
"description": bug.description,
"expected": bug.expected_behavior,
"actual": bug.actual_behavior
}
eval_tasks.append(task)优先级3:用户投诉
# 翻 Support Queue
tickets = fetch_support_tickets()
# 高频问题 = 高优先级测试用例
top_issues = tickets.group_by("issue_type").sort_by("count")
for issue in top_issues:
eval_tasks.append(issue_to_task(issue))转换示例:
# 工单
support_ticket = {
"id": "#12345",
"issue": "Agent 无法处理带特殊字符的文件名",
"steps": [
"上传文件 'report (final).pdf'",
"要求生成摘要"
],
"expected": "成功生成摘要",
"actual": "报错: Invalid filename"
}
# ↓ 转换 ↓
eval_task = {
"task_id": "special-char-filename",
"description": "处理带括号的文件名",
"input": {
"file": "report (final).pdf",
"command": "生成摘要"
},
"graders": [
{"type": "no_error"},
{"type": "output_exists"}
]
}黄金标准:
两个领域专家独立完成这个任务,会得出相同的"通过/失败"判断吗?
常见错误:
# ❌ 烂任务
task: "写一个排序脚本"
grader:
- type: file_exists
path: /tmp/sort.py # ← 你咋知道 Agent 会存这?Agent 心里苦:
- "你让我写脚本,没说存哪啊..."
- "我存 ~/sort.py 不行吗?"
- "我存 ./my_sorting_script.py 不行吗?"
结果:Agent 写了完美的排序算法,却因为文件路径被判失败。
# ❌ 烂任务
task: "优化代码性能"
grader:
- type: llm_rubric
criteria: "代码应该更快" # ← 多快算快?Agent 心里苦:
- "我优化了10%,算快吗?"
- "我优化了2倍,但可读性变差了,算吗?"
正确范例:
# ✅ 好任务
task: |
编写冒泡排序脚本,保存为 /tmp/sort.py
要求:
1. 函数名:bubble_sort
2. 输入:整数列表
3. 输出:排序后的列表(升序)
4. 不能使用内置 sort()
grader:
- type: file_exists
path: /tmp/sort.py
- type: function_test
test_cases:
- input: [3, 1, 2]
output: [1, 2, 3]
- input: []
output: []
- input: [1]
output: [1]
- type: code_check
forbidden: ["list.sort", "sorted("]# ✅ 好任务
task: |
优化 compute_stats() 函数的性能
当前baseline:处理10000条数据需要100ms
目标:降低到50ms以下(至少提升50%)
grader:
- type: performance_test
test_data: dataset_10000.csv
baseline: 100ms
target: 50ms
- type: correctness_test
# 确保优化后结果仍然正确
test: test_stats_accuracy.py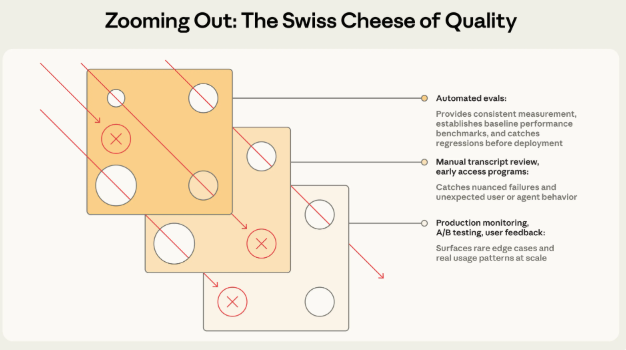
反面教材:Web Search 的翻车
初版评估(单边):
# 只测"该搜索的场景"
tasks:
- "今天北京天气如何?" → should_search: true ✓
- "最新的GDP数据" → should_search: true ✓
- "比特币当前价格" → should_search: true ✓结果:
# Agent 学到的"规律"
def should_search(query):
return True # 所有问题都搜!灾难后果:
用户:"你好"
Agent:[正在搜索..."你好"的定义]
用户:"1+1等于几"
Agent:[正在搜索..."1+1的答案"]
成本:爆炸 💰💰💰
延迟:爆炸 🐌🐌🐌
用户体验:爆炸 💥💥💥
改进版评估(双边):
tasks:
# ========== 正例:应该搜索 ==========
- query: "今天北京天气"
should_search: true
reason: "实时数据,必须搜索"
- query: "特斯拉最新股价"
should_search: true
reason: "实时数据,必须搜索"
# ========== 反例:不应搜索 ==========
- query: "苹果公司创始人是谁"
should_search: false
reason: "常识问题,模型知道"
- query: "什么是机器学习"
should_search: false
reason: "概念问题,模型知道"
- query: "1+1等于几"
should_search: false
reason: "基础数学,别浪费钱"评估指标:
# 两种失败
undertrigger = 该搜不搜(功能缺失)
overtrigger = 不该搜乱搜(资源浪费)
# 平衡指标
precision = TP / (TP + FP) # 搜的都对吗?
recall = TP / (TP + FN) # 该搜的都搜了吗?
# 综合评分
f1 = 2 * precision * recall / (precision + recall)
# 目标:F1 > 0.9目标配比:
positive_cases = 50 # 应该触发
negative_cases = 50 # 不应该触发
# 理想:50/50
# 可接受:40/60 到 60/40
# 危险:90/10(会产生偏执)环境污染的真实案例:
# 第1次试验
git init
# Agent 完成任务,提交代码
git commit -m "Solution for task #001"
# 第2次试验(忘记清理)
# Agent: "咦,git log 里有上次的答案!"
git log # 看到了上次的提交
# Agent 直接抄上次的答案
# 结果:第2次"成功率"虚高解决:
def run_trial_clean():
# 每次试验前
subprocess.run(["rm", "-rf", ".git"])
subprocess.run(["git", "init"])
# 确保干净环境# 跑10个试验
for i in range(10):
result = run_trial(task)
results.append(result)
# 结果:
# Trial 1-3: 成功 ✅
# Trial 4-7: 变慢 🐌
# Trial 8-10: 失败 ❌(内存不足)
# 原因:前面的试验没释放资源解决:
# docker-compose.yml
services:
eval-runner:
image: eval-env:latest
mem_limit: 4g
cpus: 2
restart: "no" # ← 关键:每次新容器# 第1次试验
agent.process_data()
cache.set("result", data) # 缓存了结果
# 第2次试验
agent.process_data()
# Agent: "咦,缓存里有数据,直接用!"
result = cache.get("result") # 用了上次的
# 结果:第2次"成功"是因为用了第1次的缓存环境隔离检查清单:
class EnvironmentIsolation:
"""确保每次试验环境干净"""
def clean(self):
# ✅ 文件系统
self.delete_workspace()
self.create_fresh_workspace()
# ✅ 环境变量
os.environ.clear()
self.load_env_from_config()
# ✅ 缓存
cache.flush_all()
# ✅ 数据库
db.drop_all_tables()
db.init_schema()
db.load_seed_data()
# ✅ 网络状态
# (容器内网络隔离)
# ✅ 进程
killall_previous_processes()
# ✅ 日志
logging.handlers.clear()
# ✅ 时间(如果有依赖时间的逻辑)
mock_time.set("2024-01-01 00:00:00")决策树:
这个任务有明确的客观答案吗?
│
├─ 有 → 用 Code-based Grader
│ │
│ ├─ 代码任务?
│ │ └─ 单元测试 ✅
│ │
│ ├─ 数值计算?
│ │ └─ 精确匹配 ✅
│ │
│ └─ 结构化输出?
│ └─ Schema 验证 ✅
│
└─ 没有 → 用 Model-based Grader
│
├─ 需要人类校准 ⚠️
├─ 按维度拆分评分 ⚠️
└─ 设置逃生门 ⚠️
反模式:过度刚性
# ❌ 别这么干
grader = ToolSequenceGrader(
expected=[
"search_files",
"read_file",
"edit_file",
"run_tests"
]
)
# 问题:Agent 可能有其他同样好的路径
# 比如先 run_tests 再 edit_file(TDD开发)推荐:检查结果而非路径
# ✅ 这样更好
graders = [
OutcomeGrader(
check_tests_pass=True
),
CodeQualityGrader(
rubric="quality.md"
),
SecurityGrader(
tools=["bandit", "semgrep"]
)
]
# Agent 爱怎么做就怎么做,只要结果对就行由于篇幅原因,后面步骤简化说明:
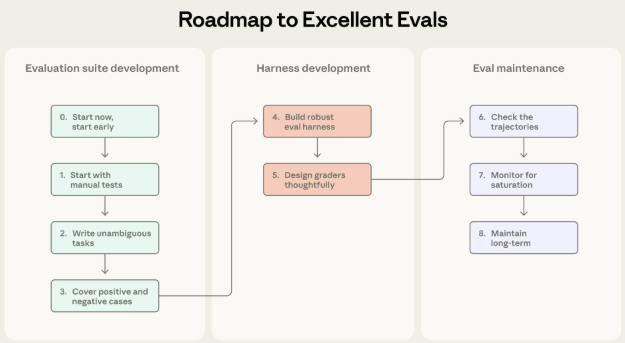
Step 6:读 Transcripts(血的教训)
不读日志 = 瞎子摸象
真实案例:CORE-Bench 的 Opus 4.5
- 初始分数:42%(垃圾?)
- 读日志发现:评分器的浮点数比较有 bug
- 修复后:95%(天才!)
Step 7:监控饱和(评估也会过时)
if eval_score > 0.85:
print("⚠️ 评估快饱和了,该加难题了")Step 8:长期维护(评估驱动开发)
产品需求 → 先写评估 → 优化Agent → 达标 → 晋升为回归测试
瑞士奶酪模型:每种方法都有"洞"(盲区),多层叠加才能堵住所有漏洞
| 方法 | 能抓住的问题 | 抓不住的问题 | 阶段 |
|---|---|---|---|
| 自动化评估 | 已知场景的回归 | 未知的边界情况 | 开发/CI |
| 生产监控 | 真实用户遇到的问题 | 上线前看不到 | 上线后 |
| A/B测试 | 整体效果提升/下降 | 具体哪里有问题 | 重大变更 |
| 用户反馈 | 意外的严重问题 | 用户懒得报的小问题 | 持续 |
| 人工审查 | 质量细节、边界case | 规模化覆盖 | 每周 |
组合策略:
┌─────────────┐
│ 自动化评估 │ ← 第一道防线(拦住明显bug)
└──────┬──────┘
↓(漏过的问题)
┌─────────────┐
│ 生产监控 │ ← 第二道防线(真实环境问题)
└──────┬──────┘
↓(漏过的问题)
┌─────────────┐
│ A/B测试 │ ← 第三道防线(整体效果)
└──────┬──────┘
↓(漏过的问题)
┌─────────────┐
│ 用户反馈 │ ← 第四道防线(用户发现)
└──────┬──────┘
↓(漏过的问题)
┌─────────────┐
│ 人工审查 │ ← 最后防线(深度检查)
└─────────────┘
不同阶段的配方:
开发前期(还没用户):
primary: 自动化评估(每次 commit)
secondary: 人工审查(每周抽样)
minimal: 内部 dogfooding首次上线:
primary:
- 自动化评估(上线前)
- 生产监控(上线后)
secondary: 用户反馈
preparing: A/B 测试基础设施规模化阶段(很多用户):
continuous:
- 自动化评估(CI/CD)
- 生产监控(实时)
- 用户反馈(持续)
regular:
- A/B 测试(重大变更)
- 人工审查(每周)
periodic:
- 人类研究(每季度)| 框架 | 一句话描述 | 适合人群 | 坑 |
|---|---|---|---|
| Harbor | 容器化评估,云原生 | 需要隔离环境的(代码执行) | 配置复杂 |
| Promptfoo | 轻量级,YAML配置 | 快速迭代,Prompt工程师 | 功能有限 |
| Braintrust | 全生命周期监控 | 需要生产观测的 | 商业产品 |
| LangSmith | LangChain 生态 | LangChain 重度用户 | 绑定生态 |
| Langfuse | 开源自托管 | 有数据合规要求的 | 需要自己运维 |
需要代码执行隔离吗?
│
├─ 是 → Harbor
│
└─ 否 → 在用 LangChain 吗?
│
├─ 是 → LangSmith / Langfuse
│
└─ 否 → 需要生产监控吗?
│
├─ 是 → Braintrust
│
└─ 否 → Promptfoo(或自己写)
先选个够用的,把精力投到写好评估任务上。
框架只是工具,任务才是核心。
一个烂框架+好任务 > 好框架+烂任务
评估的价值:
- 不是 KPI,是救命稻草
- 前期投入可见,收益长期累积
- 有评估的团队:数天迁移新模型
- 无评估的团队:数周手动测试
架构组件:
- Task + Trial + Grader + Transcript/Outcome + Harness
- Transcript 可能撒谎,Outcome 才是真相
- 评估 Agent = 评估 (Model + Harness) 组合
评分器:
- Code-based:守门员(快但傻)
- Model-based:艺术评委(灵活但需校准)
- Human:黄金标准(贵但准)
非确定性:
- pass@k:至少一次成功(有人把关)
- pass^k:每次都成功(无人把关)
工程路线:
- 尽早开始(20个就够)
- 从手测转换
- 无歧义任务
- 双边平衡
- 稳定环境
- 读 transcripts
- 监控饱和
- 长期维护
如果你还没有评估体系:
# 本周TO-DO
tasks = [
"选一个框架(推荐 Promptfoo,5分钟上手)",
"收集20个手动测试的案例",
"转成 YAML 配置",
"在 CI 里跑起来"
]
# 预计时间:1天
# 收益:无价如果你已有基础评估:
# 本月TO-DO
tasks = [
"检查任务质量(有歧义的重写)",
"读100条失败的 transcripts(找规律)",
"校准 LLM 评分器(与人类对比)",
"监控评估饱和(>85%要加难题)"
]如果你的评估已成熟:
# 本季度TO-DO
tasks = [
"建立 EDD 流程(评估驱动开发)",
"赋能产品团队贡献任务(降低门槛)",
"构建统一看板(自动化+监控+反馈)",
"定期人类研究(校准自动化系统)"
]评估不是负担,是解放生产力的工具。
没有评估:
改代码 → 手动测 → 上线 → 炸了 → 回滚 → 再改 → 循环
有评估:
改代码 → 自动测 → 通过 → 上线 → 安心睡觉 💤
评估的本质:
- 不是"证明 Agent 能力强"
- 而是"在它搞砸之前拦住它"
就像安全气囊,你希望永远用不上,但必须有。
| 类型 | 目标通过率 | 频率 | 作用 |
|---|---|---|---|
| 能力评估 | 从低爬升 | 每次迭代 | 衡量进步 |
| 回归评估 | 接近100% | 每次提交 | 防倒退 |
| 场景 | 用什么 | 注意 |
|---|---|---|
| 有单元测试 | Code-based | 最可靠 |
| 代码质量 | Model-based | 需 rubric |
| 对话质量 | Model-based | 多维度 |
| 研究扎实度 | Code-based | 引用检查 |
| 创意内容 | Human | 校准用 |
| 症状 | 原因 | 解决 |
|---|---|---|
| 0% pass@100 | 任务有问题 | 检查参考答案 |
| 分数波动 | 环境不稳定 | 加强隔离 |
| 改进不明显 | 评估饱和 | 加难题 |
| 生产不符 | 分布偏移 | 更新任务 |
# 非确定性指标
pass_at_k = 1 - (1 - p) ** k
pass_pow_k = p ** k
# 分类指标
precision = TP / (TP + FP)
recall = TP / (TP + FN)
f1 = 2 * precision * recall / (precision + recall)